
OpenAIが、ChatGPTやCodexの返事を作る裏側に関わる自前AIチップ「Jalapeño」を発表しました。半導体ニュースに見えますが、読者にとって気になるのは「ChatGPTは速く安くなるのか」です。そこを、今言えることと言えないことで分けます。
OpenAIの自前AIチップは、ChatGPTの何を変えるのか
Jalapeñoは、ChatGPTが答えを作る「推論」のために作られたチップです。今日の料金表ではなく、将来の速さ、混雑、コストに効く可能性を見るニュースです。
ChatGPTを開いて、返事が少し遅い。Codexに作業を投げて、もう少し長く安定して動いてほしい。APIを使っていて、利用料がじわじわ気になる。
そういう話の裏側にあるのが、今回のJalapeñoです。
OpenAIは2026年6月24日、Broadcomとともに、LLM推論に最適化した自社初のAIアクセラレーター「Jalapeño」を発表しました。名前だけ見るとピリッとしたチップ紹介ですが、実際にはOpenAIがモデルやアプリだけでなく、AIを動かす計算基盤まで自分たちの都合に合わせて作り始めた、という話です。
ここで大事なのは、Jalapeñoが「読者が買う新しいCPU」ではないことです。スマホやPCに載る部品の話ではありません。ChatGPT、Codex、APIのようなサービスが、ユーザーの質問に返事を作る時の裏側の話です。
だからこの記事では、チップの細かい仕様よりも、OpenAIがなぜそこまで作るのか、そして私たちの使い心地にどこまで関係するのかを見ます。
「推論」は、AIが返事を作る時間のこと
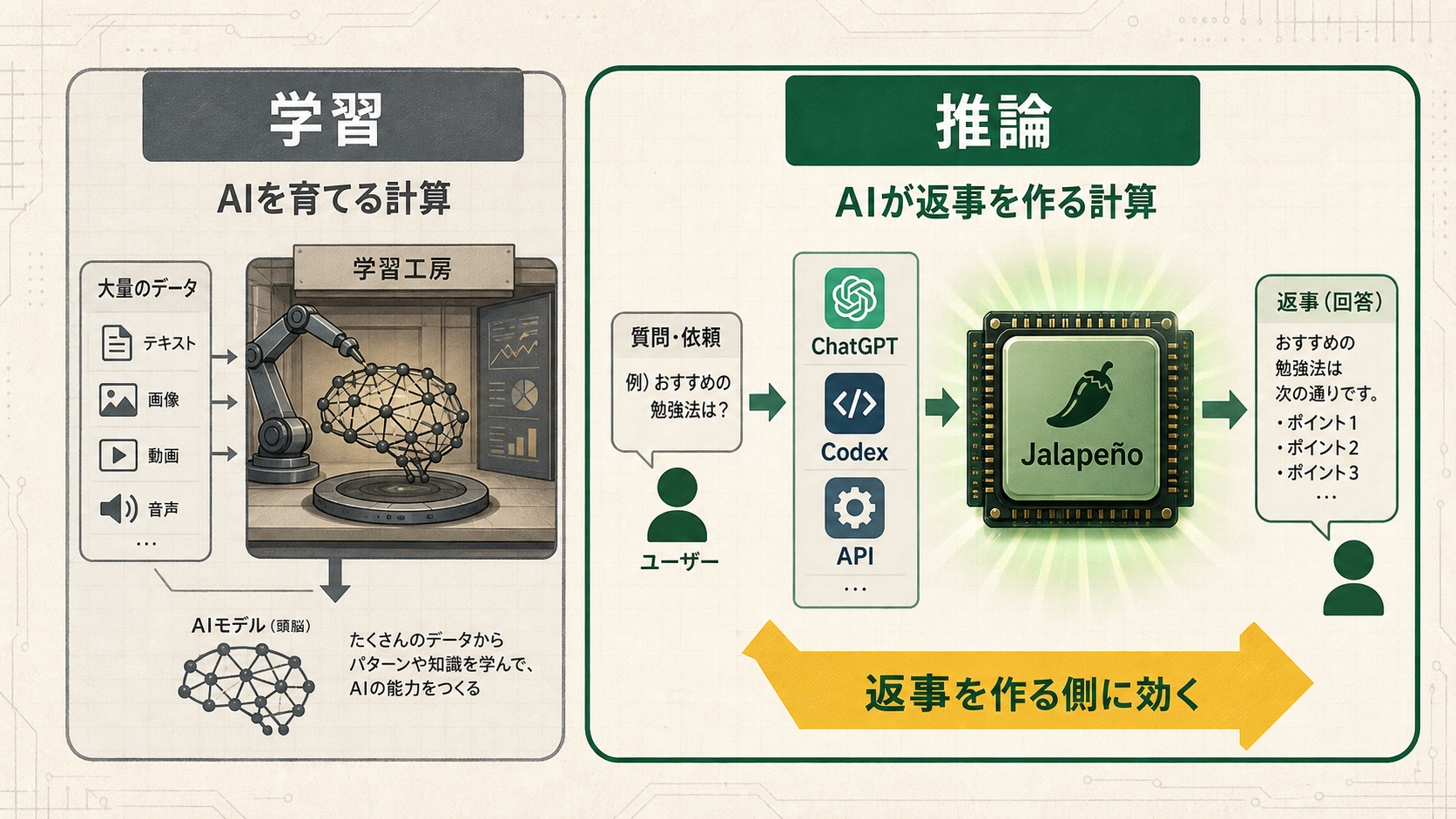
AIのチップには、AIを育てるための計算と、AIが毎回返事を出すための計算があります。Jalapeñoの主役は後者です。
AIのニュースでは「学習」と「推論」という言葉がよく出ます。難しく聞こえますが、読者目線ではこう考えると分かりやすいです。
| 言葉 | ざっくり言うと | 読者に関係する場面 |
|---|---|---|
| 学習 | AIを育てる計算 | 新しいモデルが作られる前の裏側 |
| 推論 | AIが返事を作る計算 | ChatGPTに質問した時、Codexが作業する時、APIが応答する時 |
Jalapeñoは、この「推論」に寄せたチップです。OpenAIは、ChatGPTやCodex、API、将来のエージェント製品で毎日起きる処理を見て、それに合わせて設計したと説明しています。
発表後に確認できる公式情報では、エンジニアリングサンプルがすでにラボで稼働し、GPT-5.3-Codex-Sparkを含む機械学習ワークロードを生産目標の周波数と電力で動かしているとも説明されています。ここは「構想だけ」ではない一方で、一般ユーザーのChatGPTにすぐ反映済みという意味でもありません。
つまり、派手な新モデル発表とは少し違います。新しい賢さを直接見せるニュースではありません。けれど、AIを毎日使う人にはじわっと効くかもしれない。返事を作る計算が効率よくなれば、混雑、待ち時間、コスト、使える量に関係してくるからです。
PC Watchも同日、NVIDIA製GPUの品不足が深刻化する中で、OpenAIがLLMチップを自社開発したという文脈で報じています。ここが今回の読みどころです。AIの競争は、モデル名の勝負だけでなく、裏側の計算資源をどれだけ持てるかにも移っています。
OpenAIはなぜチップまで作るのか
良いAIを作るだけではなく、そのAIを大量の人に速く安く届ける競争になっているからです。
ChatGPTのようなサービスは、ユーザーが増えるほど裏側の計算が増えます。新しいモデルが賢くなるほど、1回の返事に必要な計算も重くなりがちです。
そこでずっと主役だったのが、NVIDIAのGPUです。AIブームの中心にGPUがいるのは、AIの学習にも推論にも大量の計算が必要だからです。ただ、みんなが欲しがるものは足りなくなります。高くもなります。
OpenAIが自分たちの使い方に合わせたチップを作るのは、その依存を少しでも減らし、ChatGPTやCodexのようなサービスを大きく動かし続けるための一手です。モデル、アプリ、APIだけでなく、チップ、メモリ、ネットワーク、データセンターまで一つの流れで考える。そこまで行くと、AI企業というより、AIインフラ企業に近くなってきます。
Broadcomの発表でも、JalapeñoはOpenAIのLLM推論ニーズを踏まえたプロセッサとして説明されています。OpenAIが設計し、Broadcomがシリコン実装やネットワークで支え、Celesticaが基板やラック、システム統合に関わる形です。
ここまで聞くとかなり大きな話ですが、読者向けに言えばこうです。
ChatGPTの性能競争は、画面に出るモデル名だけではなく、裏側でどれだけ安定して返事を作れるかの競争にもなっている。
ChatGPTはすぐ速く安くなるのか
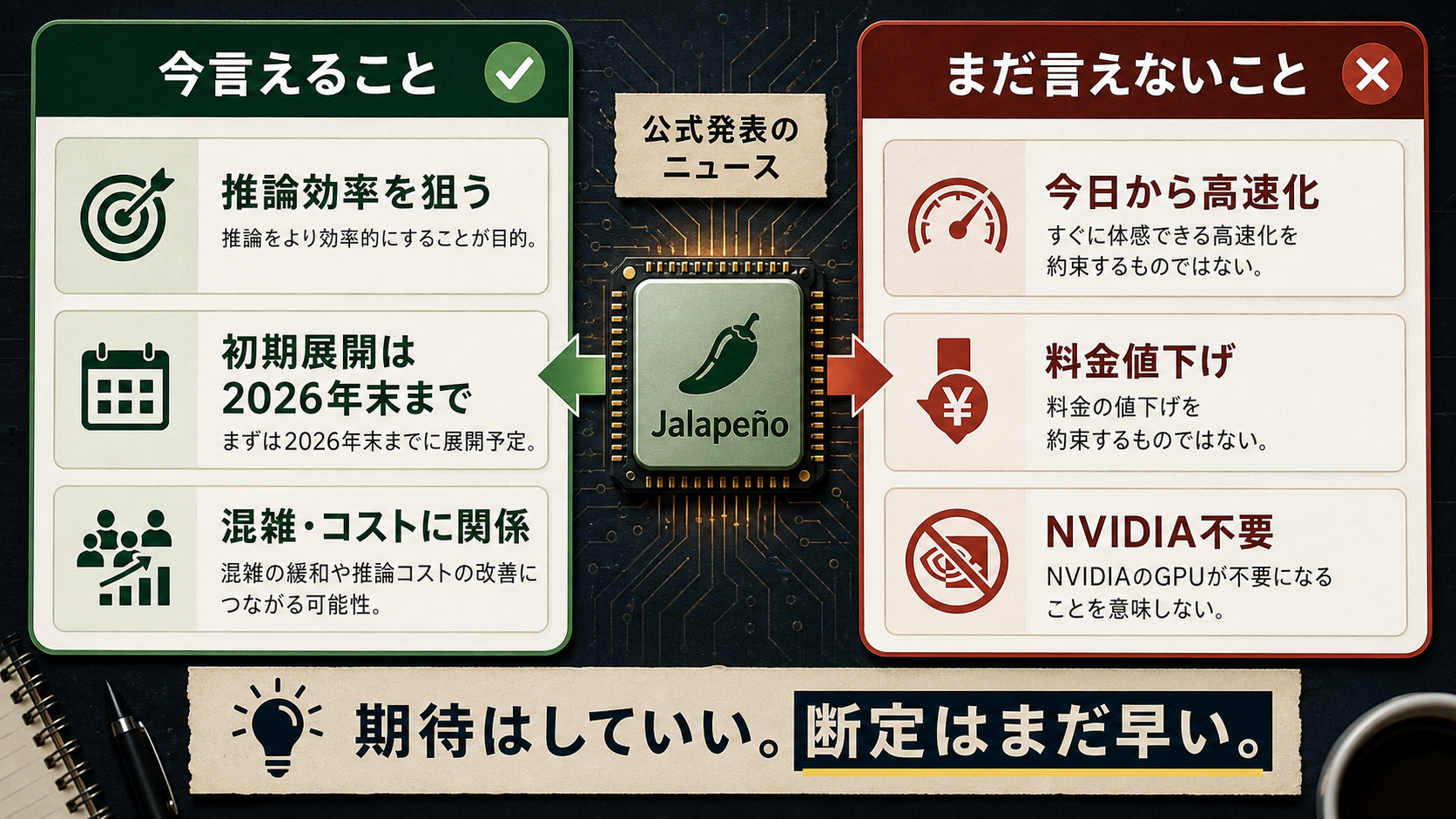
今言えるのは「効く可能性はある」。でも、今日すぐ料金が下がる、すぐ体感が変わる、とはまだ言えません。
タイトルの問いに、まず短く答えます。
速く安くなる方向には関係しそうです。ただし、現時点で「ChatGPTの料金が下がります」「今日から応答が速くなります」とは言えません。
発表後に見える材料を足しても、答えは大きく変わりません。実機サンプルはラボで動いている一方で、最終性能は測定中で、詳しい技術レポートは今後出すという段階です。初期展開も2026年末までの予定で、すぐ一般ユーザーの画面に分かる形で出る話ではありません。
| 見方 | 今言えること | まだ言えないこと |
|---|---|---|
| 速さ | 推論効率を上げる狙いはある | 今日からChatGPTが速くなるとは言えない |
| 料金 | コスト効率に関わる可能性はある | ChatGPTやAPIの値下げは未確認 |
| 安定性 | 大規模展開で混雑対策に効く可能性はある | いつどのサービスで体感できるかは未確認 |
| NVIDIA依存 | 依存を下げる方向の一手 | NVIDIAが不要になるとは言えない |
ここを盛りすぎると、記事としては気持ちよくても、事実から外れます。
Jalapeñoは「ChatGPTが明日から別物になる発表」ではありません。むしろ、ChatGPTをもっと大きく、もっと安定して動かすために、OpenAIが地面を作り始めたニュースです。家で言えば、新しい部屋を見せたというより、電気と水道の配管まで自分で設計し始めたような話です。
名前より見るべきは「AIを動かす値段」
Jalapeñoという名前より大事なのは、AIの便利さを支える電気代、待ち時間、サーバー不足の問題です。
普通にChatGPTを使う読者からすると、チップ名は覚えなくても困りません。Jalapeñoと聞いて「辛そう」くらいで止まっても大丈夫です。
でも、AIの使い心地が裏側の計算に左右されることは、これからもっと見えやすくなります。混雑している時に遅い。無料枠や上限がある。高性能モデルほど使える回数が限られる。APIで作るサービスのコストが気になる。Codexに長い作業を任せると、計算資源がかなり必要になる。
そういう現実があるから、OpenAIは自前の計算基盤を増やしたい。AIが人の仕事を助けるほど、AI自身を動かすコストが大きくなるからです。
もう一つの見どころは、OpenAIが最初の議論から9カ月で、製造へ回せる設計データを出す「テープアウト」まで進めたと説明している点です。これは「ChatGPTが今日速くなった証拠」ではなく、AI企業がAIを動かす基盤づくりのスピードまで競争し始めた、という読みどころです。
- ChatGPTを使う人: すぐ値下げではないが、将来の応答速度や安定性の土台になる可能性がある。
- Codexを使う人: 長い作業をAIに任せるほど、推論効率の意味が大きくなる。
- APIを使う人: 価格や上限に直結するとは限らないが、サービス提供側のコスト構造には関係しうる。
- AIニュースを追う人: これからはモデル名だけでなく、チップ、電力、データセンターも競争の主役になる。
つまり、Jalapeñoのニュースは「OpenAIが半導体会社になった」というだけではありません。AIが日用品になっていくほど、裏側の計算機まで取りに行かないと、速さも安さも安定性も保ちにくくなる。そこが本筋です。
今回の発表は、まだ「準備が始まった」段階
期待はしていい。ただし、読者が今日チェックするべきなのは「いつ安くなるか」より「OpenAIが何を握ろうとしているか」です。
Jalapeñoは、今日から私たちの手元で動くチップではありません。公式発表でも、初期展開は2026年末までとされています。性能の詳細も、これから出る技術レポートを待つ段階です。
それでも、このニュースは小さくありません。AI企業が「モデルを作る」「チャットアプリを出す」だけでなく、返事を作るためのチップまで作る。ここまで来ると、AIの競争はかなり重たい産業になってきます。
読者としては、次のニュースで料金や機能だけを見るのではなく、裏側の計算資源も少し見ておくと分かりやすくなります。なぜ使える回数に制限があるのか。なぜ高性能モデルは高いのか。なぜAI企業がデータセンターや半導体の話ばかりするのか。
今回のJalapeñoは、その答えの一部です。
ChatGPTが速く安くなるかどうかは、まだ断定できません。ただ、OpenAIがそこに効く場所まで自分で作り始めたことは、かなり大きな変化です。






コメント