
SD3 (Stable Diffusion 3) のローカルでの使い方とダウンロード方法も記載。SDXLとの違いやSD3のこれからの期待について話します。
ついに来た SD3

今回リリースされたのは4種類ある中の "1つ"
もともとSD3はAPIを通じて有料で利用できましたが、Stability AIは2024年6月12日に "SD3 Medium" を無料公開しました。
SD3 Mediumを実際に生成してみた
現時点では全く期待していませんが、とりあえず生成してみます。推奨解像度は1024x1024でSDXLと変わっていません。
プロンプトはClaude3で適当に考えてもらったものを採用。






特に細かい描写の品質は格段に上がっています。指の本数や尻尾が多かったりすることはありますが、SD3はSDXLと比べて着実に進化していると言える気がします。
SD3のダウンロード先の解説
ダウンロード先 - Civitai, Hugging Face
どれをダウンロードすればいいの?

Text Encoder が内蔵されているモデルと、内蔵されていないモデルがあります。
Text Encoder が内蔵されているモデルはこれだけあれば他のものをダウンロードする必要が無いのでおすすめです。
Text Encoder が内蔵されているモデルは次の2種類です。fp8版とfp16版があります。
- SD3 Medium Incl T5XXL (10.12GB) ※FP8版
- SD3 Medium Incl Clip FP16 (14.68 GB) ※FP16版 "高精度"
fp8版はVRAMが8GBあれば動作するみたいです。
Text Encoder を別途用意したい方は SD3 Medium (4.34GB) に加えて、Text Encoderをダウンロードします。
- Text Encoder - Clip L (234 MB) 必須
- Text Encoder - Clip G (1.29 GB) 必須
- Text Encoder - T5 e4m3fn (4.56 GB) 選択 ※FP8
- Text Encoder - T5XXLFP16 (9.12 GB) 選択 ※FP16
またSD3のワークフローもダウンロードできるので、ComfyUIユーザーはそちらもダウンロードしておきましょう。
モデルをダウンロードするには Hugging Face の登録と氏名などの個人情報を提供する必要があります。
どれをダウンロードすればいいの?
Text Encoder が内蔵されているモデルと、内蔵されていないモデルがあります。
Text Encoder が内蔵されているモデルはこれだけあれば他のものをダウンロードする必要が無いのでおすすめです。
Text Encoder が内蔵されているモデルは次の2種類です。fp8版とfp16版があります。
- sd3_medium_incl_clips_t5xxlfp8.safetensors (10.9GB) ※FP8版
- sd3_medium_incl_clips_t5xxlfp16.safetensors (15.8GB) ※FP16版 "高精度"
fp8版はVRAMが8GBあれば動作するみたいです。

Text Encoder を別途用意したい方は sd3_medium.safetensors (4.34GB) に加えて、text encoders フォルダの中身をダウンロードします。
text_encodersフォルダをクリック
clip_gとclip_lは必須です。
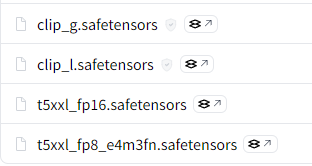
- clip_g.safetensors (1.39 GB)
- clip_l.safetensors (246 MB)
- t5xxl_fp16.safetensors (9.79 GB) ※FP16
- t5xxl_fp8_e4m3fn.safetensors (4.89 GB) ※FP8
またSD3のワークフローもダウンロードできるので、ComfyUIユーザーはそちらもダウンロードしておきましょう。
Text Encoderの保存先どこやねん
ComfyUIなら "clip" フォルダーに保存します。
ComfyUI/
└── models/
└── clip/
├── put_clip_or_text_encoder_models_here
├── clip_g.safetensors
├── clip_l.safetensors
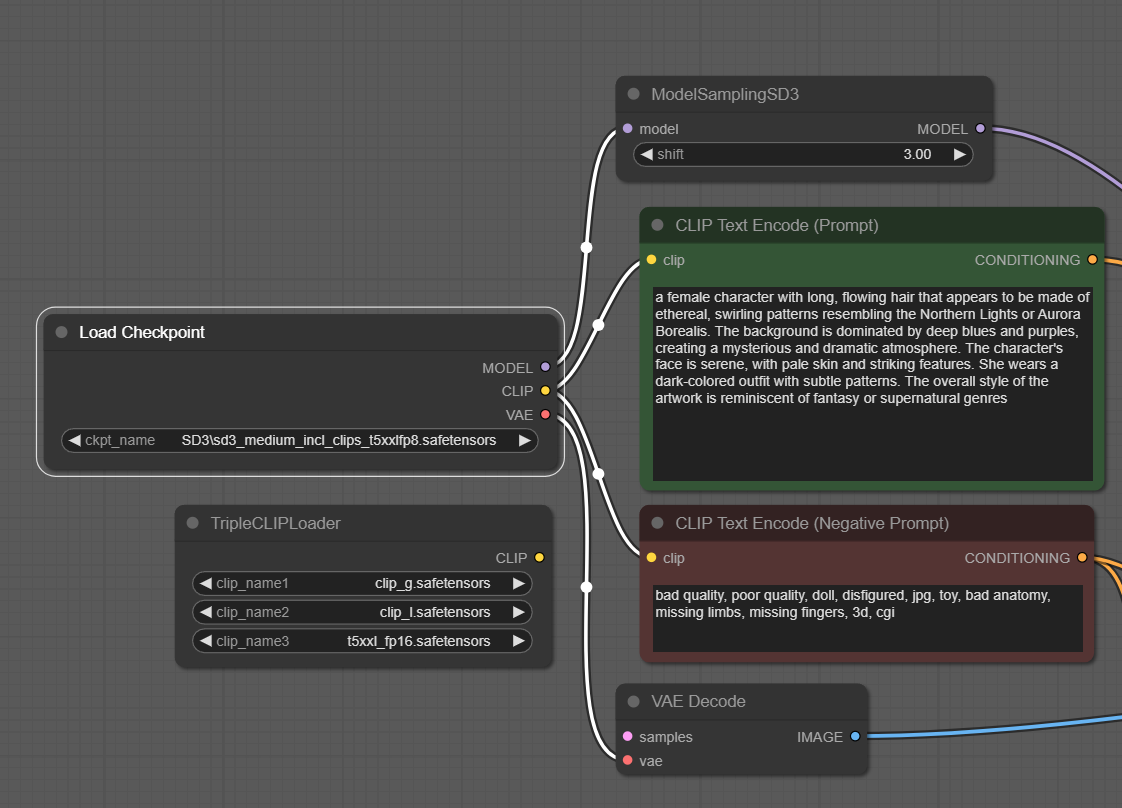
└── t5xxl_fp16.safetensorsText Encoderが内蔵されたSD3を使う場合
今まで通り Load Checkpoint からCLIPを使ってください。全てのSD3モデルに言えることですがVAEも内蔵されています。
Medium以外のSD3モデルについて
無料公開予定のSD3リスト
- SD3 Small / 1B
- SD3 Medium / 2B(今回のモデル 2 Billion Parameter, 20億パラメーターモデル)
- SD3 Large / 4B
- SD3 Huge / 8B

全てのモデルがファッキン無料公開!?ソースは?
こちらのRedditにてStability AI社の従業員が発言していました。確定ではないですが無料になる可能性は非常に高そうです。
しかし営利目的の場合はファッキン有料らしいのでライセンスの確認が必要そうです。
ふーん。色々あるけど結局8Bモデルが高性能なんでしょ?
参考:Reddit
十分に学習された Smaller モデルは、学習不足の Larger モデルよりも優れた性能を発揮する可能性があります。
しかし、8Bモデルが十分に学習されれば、2Bモデルを上回る性能を発揮するはずです。とのこと。
ですが、8BモデルはVRAMが24GB必要になりそうなので、主流は2Bか4Bになる気がします。

2Bモデルだと設定次第では6GBでもいけるらしい。いやほんまかいな。
これからのSD3に期待できること
派生モデルに期待
SD3はアニメライクな画像は苦手ですが、第三者による派生モデルの制作は既に始まっているので期待して待ちましょう。
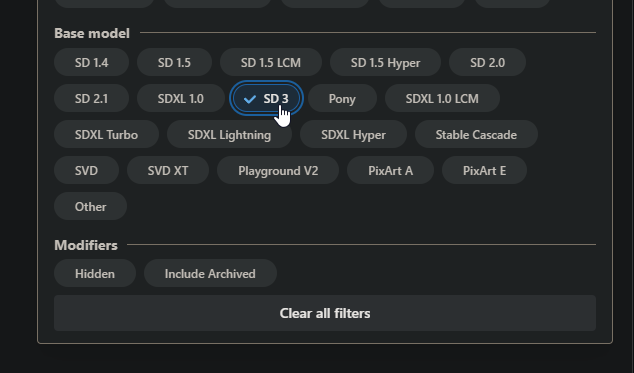
基本的に派生モデルは "Civitai" にアップロードされるので定期的なチェックがおすすめです。
右上の "Filters" からSD3を選択することで絞り込むことができます。
SDXLとは構造が全然違う感じ?期待はできそう?
参考:Reddit
SDXLとSD3は構造が大きく異なります
SDXLはSD1.xと同じく、UNetアーキテクチャを使用しています。SDXLの主な改良点は、モデルサイズの拡大(パラメータ数の増加)と、高品質なデータセットを用いた再学習です。これにより、SDXLは画質とプロンプト忠実性において、SD1.xを上回る性能を達成しました。
一方、SD3はTransformerベースのアーキテクチャを採用しており、LLMと似た構造を持っています。この新しいアーキテクチャにより、SD3はマルチモーダル学習に適しており、テキストだけでなく画像、音声、動画などとの関連性をより深く理解できます。また、16チャンネルのVAEを用いることで、低解像度でも高品質な画像生成が可能となっています。
SD3への期待は3点
- 高い柔軟性とコントロール性:SD3のアーキテクチャは、LoRAやアダプターなどの手法との親和性が高く、ユーザーは自分の好みに合わせてモデルをカスタマイズしやすくなります。
- マルチモーダルAIの発展:SD3はテキスト、画像、音声、動画などを統合的に扱えるため、様々なタイプのコンテンツ生成に応用できます。
- コミュニティの発展:SD3のシンプルで強力なアーキテクチャは、AIリサーチャーや開発者を引き付け、コミュニティの発展を促進すると期待されています。
なんだか良くわかりませんがすげぇらしいです。派生モデルが登場するのはどれくらい先なんでしょうか。本格的なモデルが登場するのは3か月程掛かると予想していますが、どうなるんでしょうね。







なんでも掲示板
コメント一覧 (2件)
-
-
このフォームは reCAPTCHA によって保護されており、Googleのプライバシーポリシーと利用規約が適用されます。最近やっとXLに移行したのにもうSD3が公開されてビックリです
丁寧な解説ありがとうございます
いつも参考にさせていただいています
XLも派生モデルの開発がまだ進んでいるみたいなので、どちらもチェックすることになりそうです。