
Impact Packの基本的な使い方を解説している記事です。顔をもっと綺麗に仕上げたい人は必見のカスタムノードになっています。設定項目を細かく解説しているので使い込みたい方も参考になると思います。
人によっては必須級「Impact Pack」
この記事で紹介する「Impact Pack」というカスタムノードでは、指定した部位を自動的に検出して再生成することができます。
今回は主に ”顔” を自動検出して再生成する方法を紹介します。
例:1

LoRAを変えて再生成

例:2

LoRAを追加して再生成 / プロンプトも大きく変更

例:3

LoRAを変えて再生成

inpaintとの違いとヤバすぎるメリット
”inpaint” は一部を修正するために「全体」を再生成するのに対して
”Impact Pack” は「一部だけ」再生成します。また、その再生成する部分の解像度は ”自由に変更が可能” です。
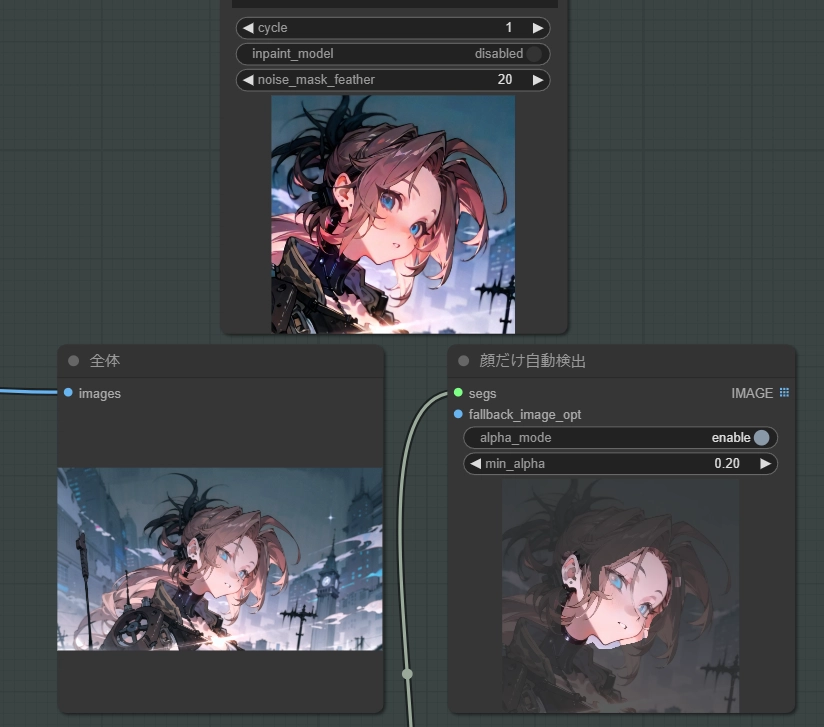
使い込んでいる人はこの時点で何がやばいのか分かるかもしれません。
計算リソース・時間を削減できる
「全体」を再生成するより、「一部」を再生成して修正したほうがリソースは削減できます。これは条件によって差が非常に大きいですが、大抵の場合 "半分以下" に計算コストを抑えられます。
また、顔を自動検出してマスクも自動で作ってくれるので、自分でマスクを作る必要がありません。※自分でマスクを作ることも可
どんな構図でも顔の解像度を高くできる
この機能が本当に革命的だと思いました。
今までは顔の書き込み量を増やそう思ったら、全体の解像度を上げるしか選択肢はありませんでした。
顔の書き込み量が少ないなら全体の解像度を上げればいいじゃん!と、殆どの人が考えて実際にやったことがあると思います。
実際は、顔の解像度が上がりきる前に全体が崩壊してきます。また、LoRAを入れることによる顔以外への影響も問題でした。
元画像(顔の解像度が低い)

Impact Packを使って顔を修正

大きい解像度(2304x2304)で生成

LoRAやモデル、プロンプト、VAEなど全て変えて再生成
タイトルにはLoRAとモデルしか書いてませんが、実際はControlNetを含むほぼすべての設定を "指定した部位のみ" 変更して再生成することができます。
この工程は本当に無限に組み合わせを考えられるのでとにかく時間が掛かります。これは、デメリットであると同時にメリットでもあります。
しかし直接的に生成する画像の品質に関わってきますので、使う価値は非常に高いと考えています。
Impact Packのインストール方法
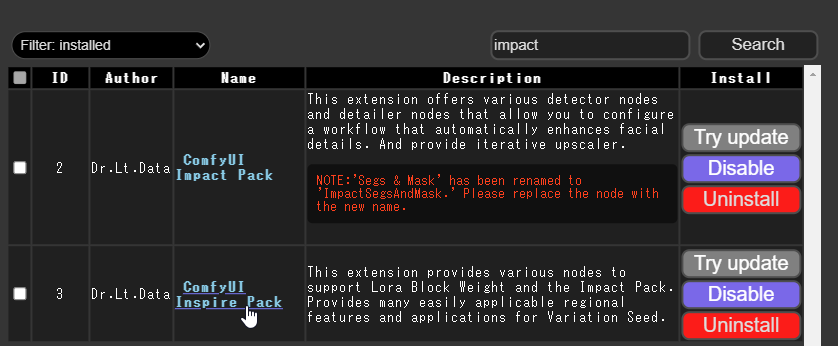
お馴染みのComfy Managerからインストールできます。
”Impact Pack” と ”Inspire Pack” の2つが出てきますが、ControlNetを使うためには ”Inspire Pack” も必須なので必要そうだと思ったらこちらもインストールしておきましょう。
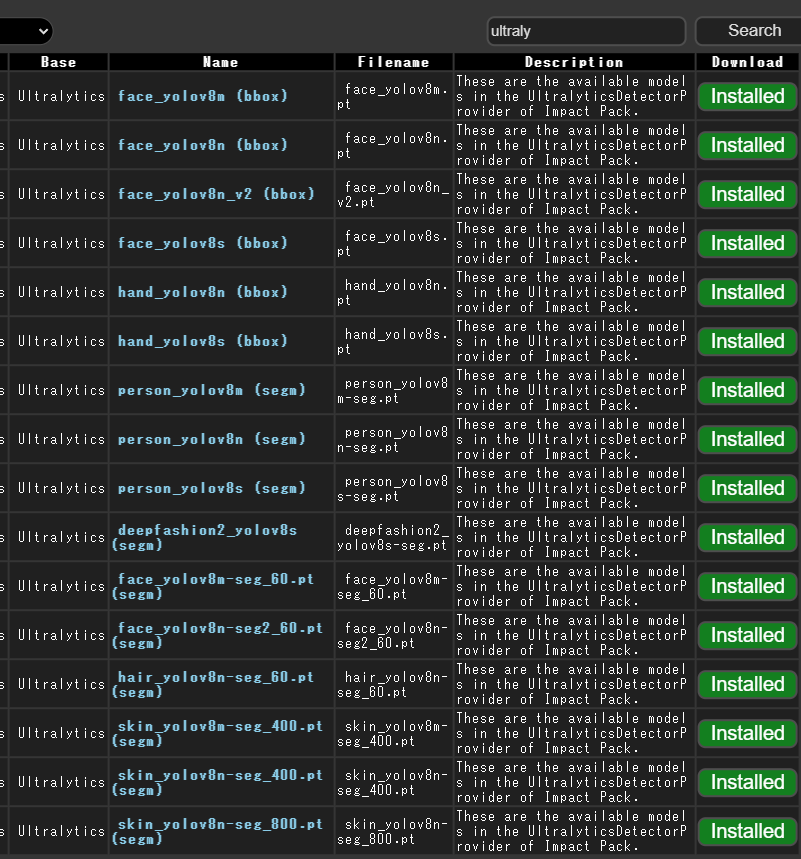
また、Install Models からDetector(顔の自動検出機能)に必要なモデルもダウンロードしておきます。
使い方解説・ワークフローの構築
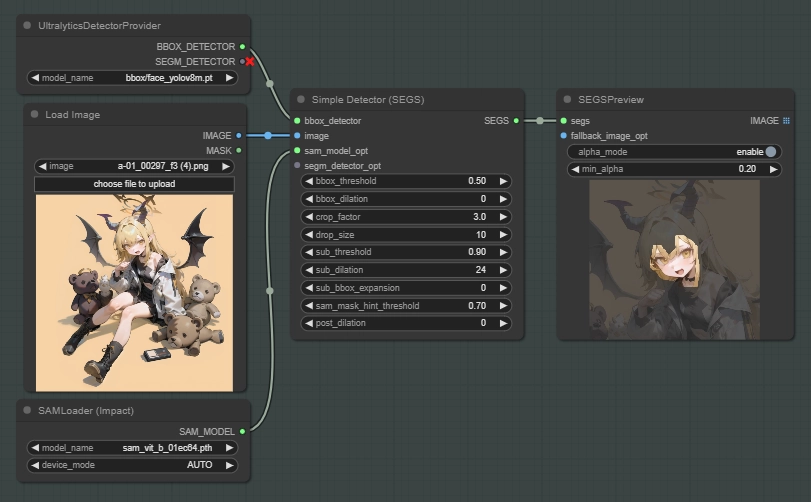
では細かい設定は考えずに、顔を再生成するためのワークフローを作っていきましょう。
まだ用語は理解しなくて大丈夫です。
なんでもいいので、顔を再生成したい画像を用意します。
取りあえずやってみないと何も掴めないと思うので、本当に適当な画像で大丈夫です。
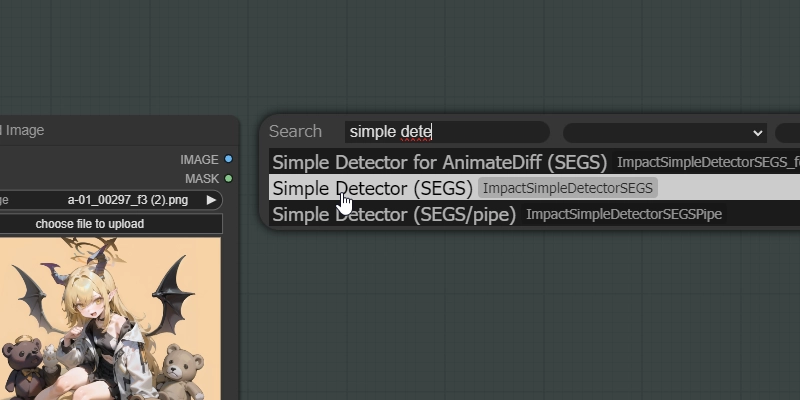
一応ノードの出し方について触れておきます。
何もない箇所でダブルクリックすると検索ボックスが表示されます。特定のノードを出したい場合には非常に便利なので覚えておきましょう。
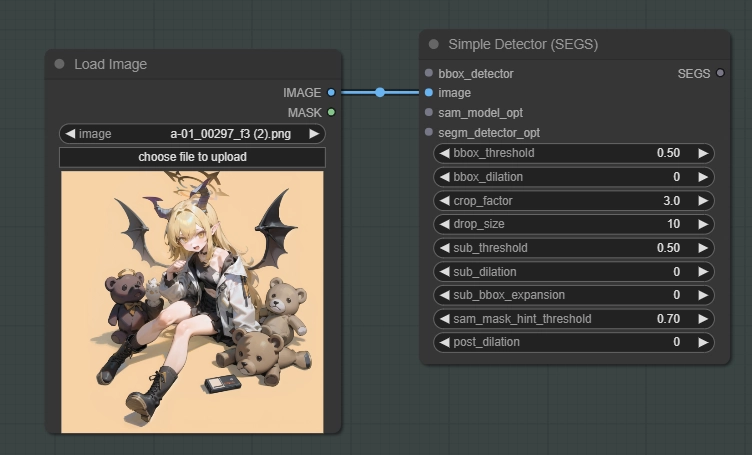
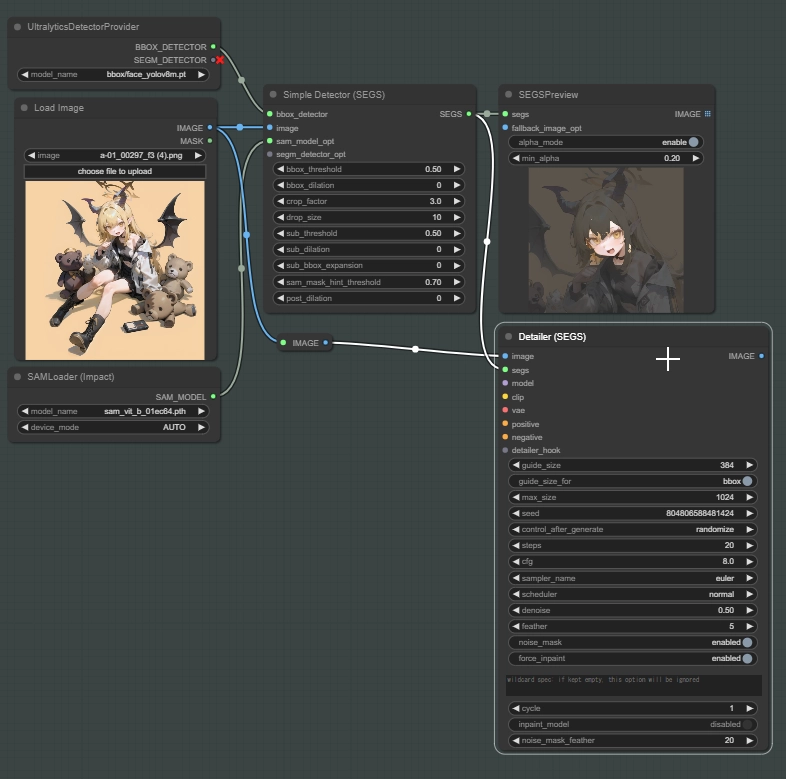
イメージソースとDetectorノードを繋ぎます。
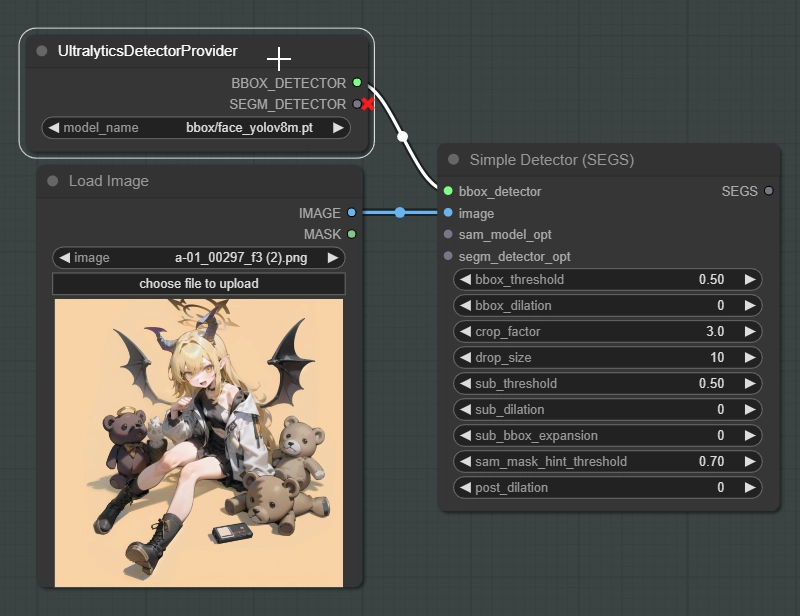
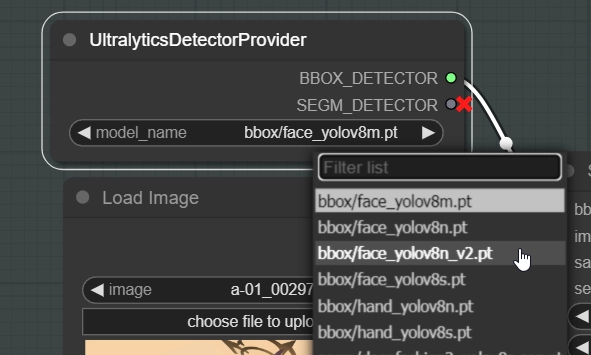
このノードはBBOXとSEGMモデルが選択できます。SEGMは今回使わないので無視してください。
顔が検出されない場合はこのモデルを変更して再度試すことができます。bbox/faceと書かれているモデルを選択します。
もしそれでも顔が検出されない場合は "Detectorの設定" に飛んでください。
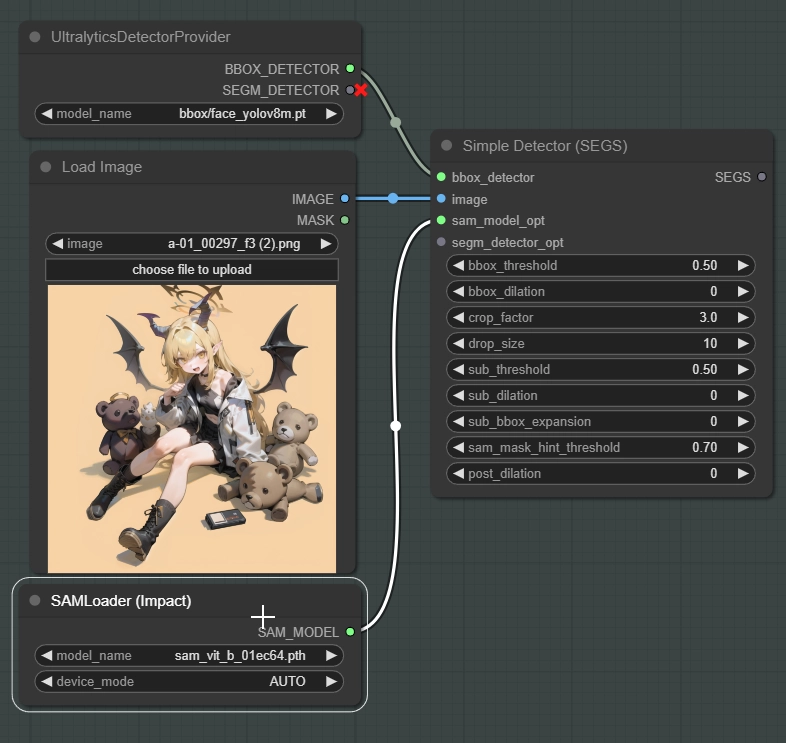
デフォルトで既にSAMは入っていますが、もし無い場合はComfyUI ManagerからSAMをダウンロードできます。

”SEGM” と ”SEGS” は綴りが似ていますが違うものなので注意してください。SEGSはSEGMを含む、BBOX、SAMなどの情報を含んだデータです。
SEGSPreviewをDetectorと繋いだらQueue Promptからこのワークフローを実行します。Simple Detectorの設定はとても重要ですが、とりあえずどんなものか確認したいと思うのでデフォルト設定で一度生成してみましょう。
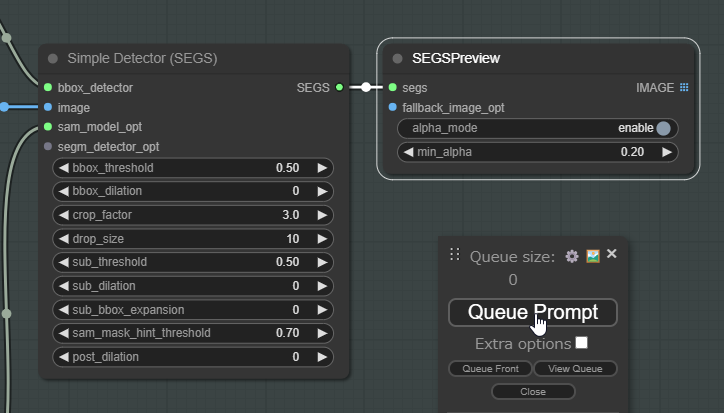
Detectorで顔を検出しているか確認します。
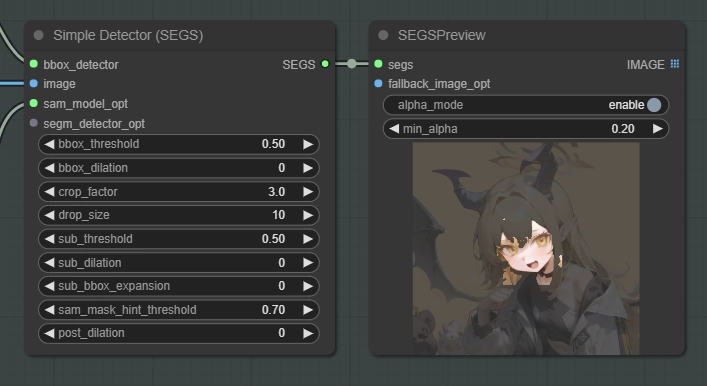
Detailerは内部的にKSamplerを利用して画像のinpaintを行います。
なので ”segs” 以外の入力ポートであるmodel、clip、vae、positive、negativeはKSamplerと同じ扱いで大丈夫です。
detailer_hookは基本使わないので無視してください。
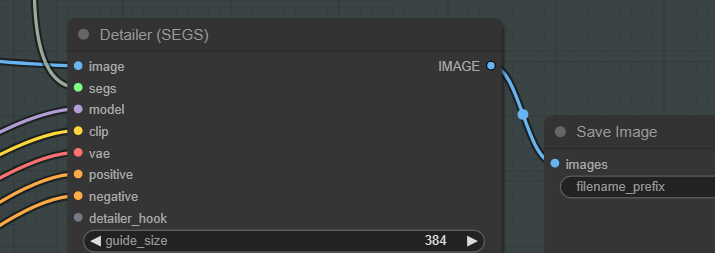
後はDetailerの出力ポートにSave ImageノードやPreview Imageを繋いで生成してみましょう。ここまででワークフローの構築は以上になります。
完全にデフォルト設定で顔を再生成してみました。既に調整済みのモデルやプロンプトを使用しているのでデフォルト設定でも整った顔になりますが、モデルやLoRA、プロンプトの選定だけでも今まで経験したことのない調整が必要なので色々試してみてください。思ったより難しいですが結構楽しいですよ。
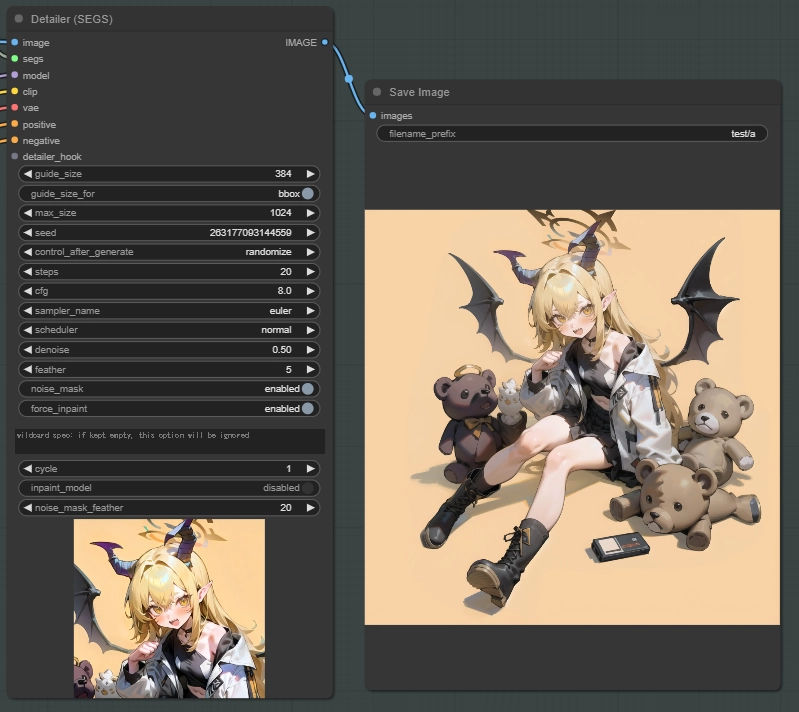
次の項では用語の解説をしますが、読まなくてもギリギリ何とかなると思います。その次にSimple DetectorとDetailer (SEGS)の設定の解説をしていきます。
設定を煮詰めて最終的に出来たもの

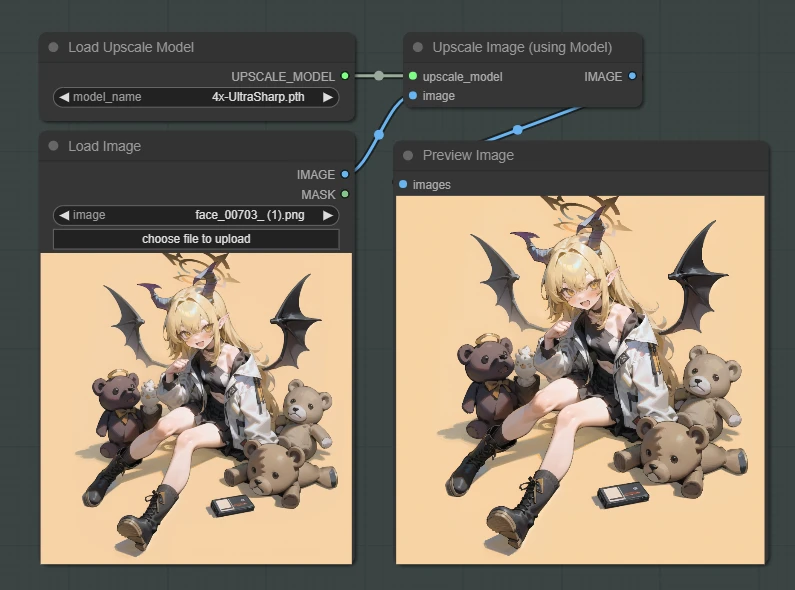
顔周辺の解像感が少し物足りなくなる場合があります。
その場合は "4x-UltraSharp" がおすすめです。こちらもComfyUI Managerからダウンロードできます。
用語の解説
Detectorとは?
Detectorは特定の領域を検出し、masks、bbox、crop regions、confidence、label、controlnet情報などを含む "SEGS" という形式で処理されたデータを返します。
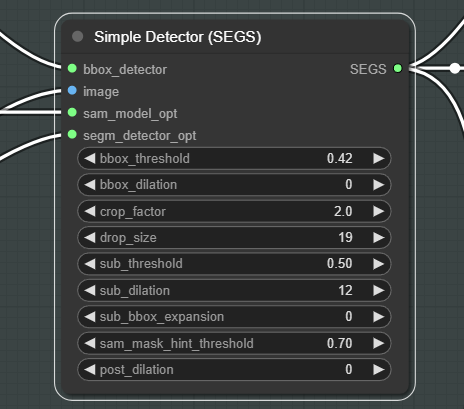
BBOX
BBOX(Bounding Box)は検出領域を矩形で捉えます。例えば、bbox/face_yolov8m.ptモデルを使用すると、顔の矩形領域のマスクを取得できます。
SAM
SAM(Segment Anything Model)は、Segment Anythingの手法を用いてシルエットマスクを生成します。単独では使用できませんが、BBOXモデルと組み合わせて検出対象を指定することで、検出された物体の詳細なシルエットマスクを作成できます。
SEGM
SEGM(Segmentation)は検出領域をシルエットとして捉えます。例えば、segm/person_yolov8n-seg.ptモデルを使用すると、人物のシルエットマスクを取得できます。
BBOXとSAMとSEGMの違い

BBOXは大まかに特定の範囲を指定します。

SAMとSEGMはより正確で詳細な物体の領域を特定しようとするシステムです
SEGMは特定のタスクに特化した精度重視のモデルで、SAMは柔軟性と汎用性に優れた新しいセグメンテーションモデルです。
ComfyUI Managerからダウンロードできる "SEGMモデル" はリアル調に特化しているので基本的にアニメ系モデルはSAMを使うことになると思います。
SEGS
SEGMとSEGSは綴りが似ていますが違うので注意してください。SEGSはSEGMを含む、BBOX、SAMなどの情報を含んだデータです。
Detailer (SEGS)の設定
Detectorの設定も重要ですが、Detailerの設定の方が最初は圧倒的に重要なのでこちらの設定を変えていきましょう。
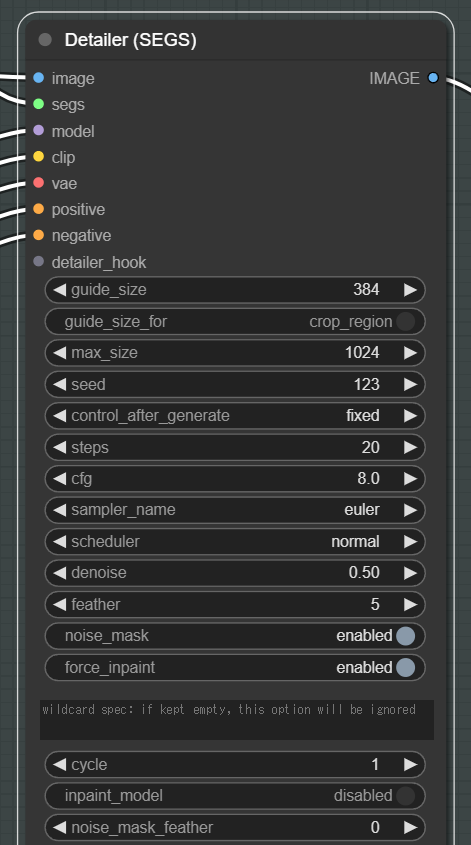
一番重要な設定は上から順の3つです。
guide_size:Detailerの基準となるサイズで、再生成する部分の解像度を変更できます。guide_size_forの選択によって大きく変わります。
実際に変更されているかどうかコンソールで確認できます。guide_sizeを720にして実際に確認してみます。
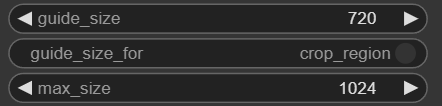
720が基準となり再生成が実行されています。

guide_size_for:guide_sizeの基準を、bboxかcrop_regionのどちらにするかを決める設定。
デフォルトではbboxになっていますが、調整が難しい為crop_regionがおすすめです。
max_size:画像の最大サイズを制限する設定です。想定以上に大きい画像が作られることを防ぐための設定なので、基本的に一度設定すると変えることはありません。
この項目は全てKSamplerと同じなのでこの記事では省略します。
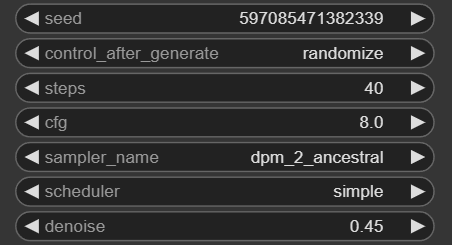
feather以外の設定は使い道がよく分からなかったので説明のみ載せておきます。
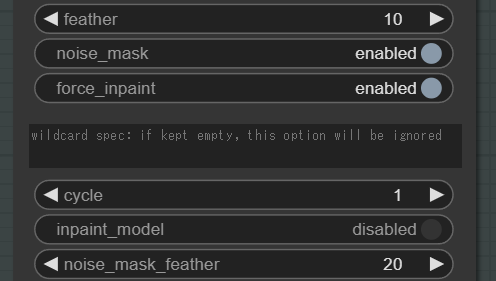
feather :再生成した画像を元の画像に自然に合成するための、境界のぼかし効果の設定です。数値を大きくすればより境界がぼけるようになります。
noise_mask:修復する領域を、マスクされた部分のみに限定するかどうかの設定。ONにすると、マスク部分のみが修復されます。
force_inpaint:guide_sizeより小さくても、強制的に再生成を行う設定。プロンプトを変更する場合などに使用します。
cycle:Detailerでサンプリングを適用する反復回数を決定します。Detailer hookと併用すると、途中でノイズを加えたり、徐々にdenoiseサイズを減らしたりすることができます。
noise_mask_feather:インペインティング処理に適用されるマスクにfeatherをかけるかどうかを決定します。必ずしも自然な画像になるとは限らず、エッジにアーティファクト(斑点やノイズ)を作る可能性もあります。
Simple Detector (SEGS)の設定
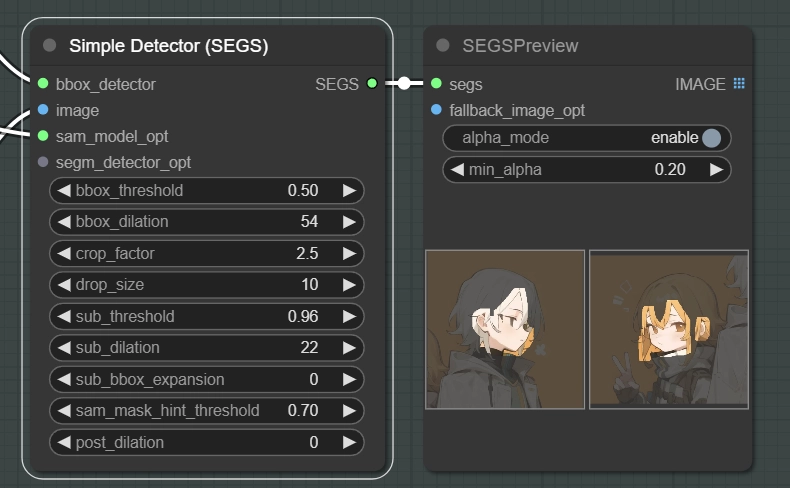
こちらも重要な設定ですので、それぞれ解説していきます。
まず一番重要なcrop_factorを先に解説します。
crop_factorは検出されたバウンディングボックスの周囲をどの程度広げてトリミングするかを決定するパラメータです。
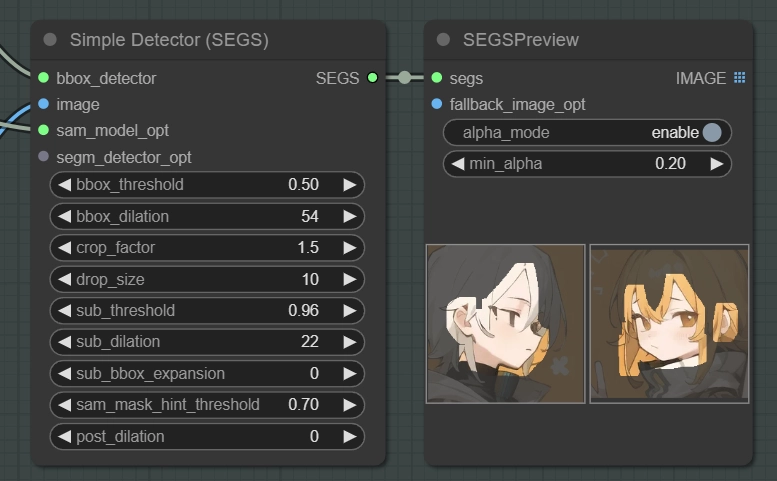
crop_factorを下げるとトリミング範囲が狭くなり、
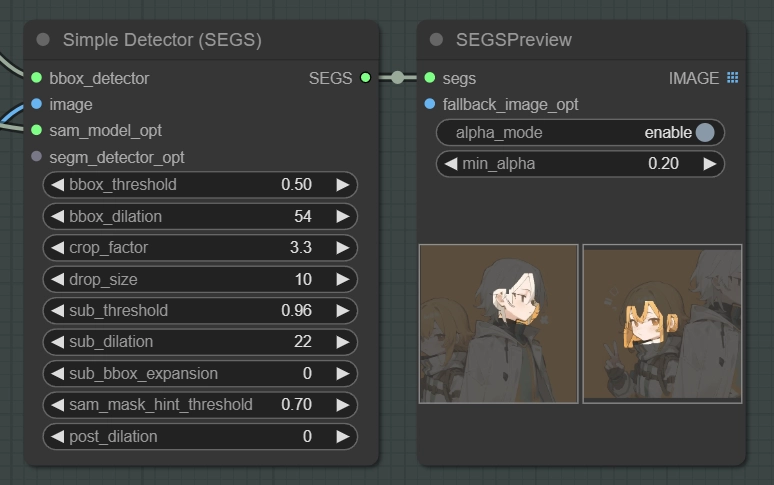
crop_factorを上げるとトリミング範囲が広くなります。
個人的にこの設定は非常に面白いと思っていて最適解というのは間違いなく存在しない項目だと思っています。
2.5前後がいい結果になりやすい印象です。
bbox_thresholdとsub_thresholdについて
threshold(閾値)は、物体検出の信頼度スコアに関連するパラメータです。
物体検出モデルは、画像内の物体を検出すると、各検出結果に対して信頼度スコア(0から1の範囲)を割り当てます。このスコアは、モデルがその検出結果をどの程度確信しているかを示します。
threshold パラメータは、この信頼度スコアの最小値を設定します。つまり、threshold 以上の信頼度スコアを持つ検出結果のみが、後続の処理(セグメンテーション、マスク生成など)に使用されます。
例えば、threshold が 0.5 に設定されている場合、信頼度スコアが 0.5 以上の検出結果のみが処理の対象となります。これにより、誤検出や信頼度の低い検出結果を除外し、処理の精度を向上させることができます。
ただし、threshold を高く設定しすぎると、本来検出されるべき物体も除外される可能性があります。逆に、threshold を低く設定しすぎると、誤検出が増加する可能性があります。
bbox_thresholdは "BBOX" の閾値で、sub_thresholdは "SAM" の閾値です。
例えばbbox_thresholdの値を上げると、顔では無いのにBBOXが反応して、マスクを生成してしまった場合や、小さい顔が反応してマスクを生成してしまった場合、この閾値を上げることでメインキャラクターのみマスクを作成することができます。
sub_thresholdはSAMの信頼度スコアに影響します。
sub_thresholdが低い場合は信用度スコアが低い物体も検出します。
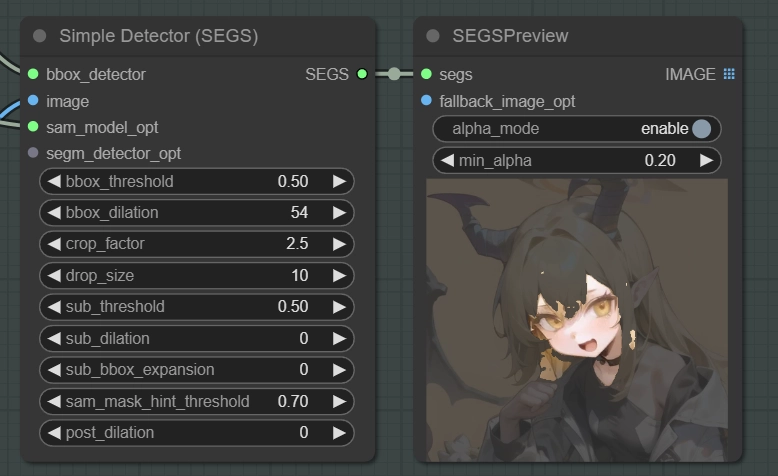
sub_thresholdが高い場合は信用度スコアが高い物体しか検出しませんので、余分なマスクを減らすことができます。
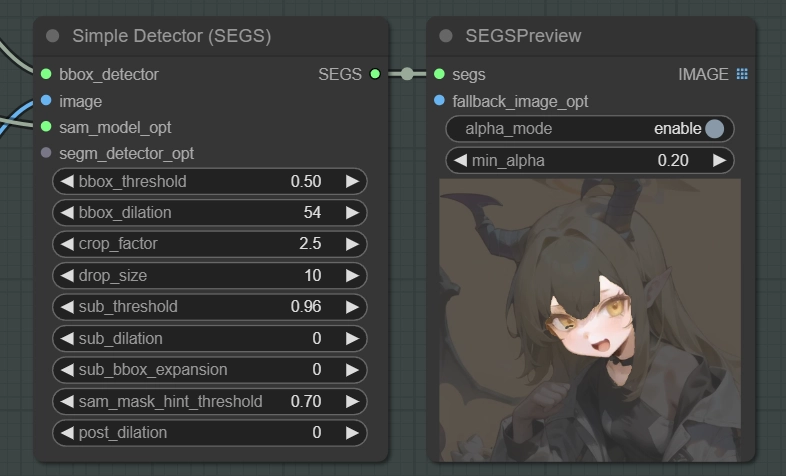
drop_size:指定されたサイズよりも小さいマスクを無視するようにモデルに指示するための設定です。
このように群衆の中にメインキャラクターがいる場合、群衆の顔にもマスクが生成されてしまいます。
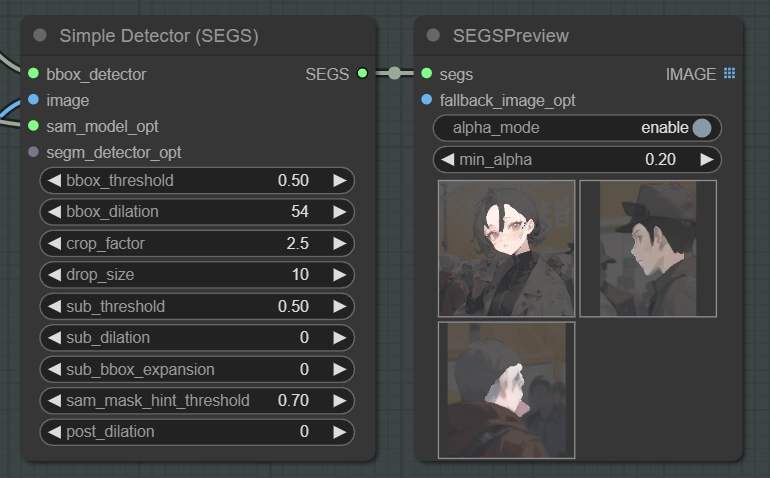
この場合にはdrop_sizeを上げることでこの値よりも小さいマスクは無視するようになります。
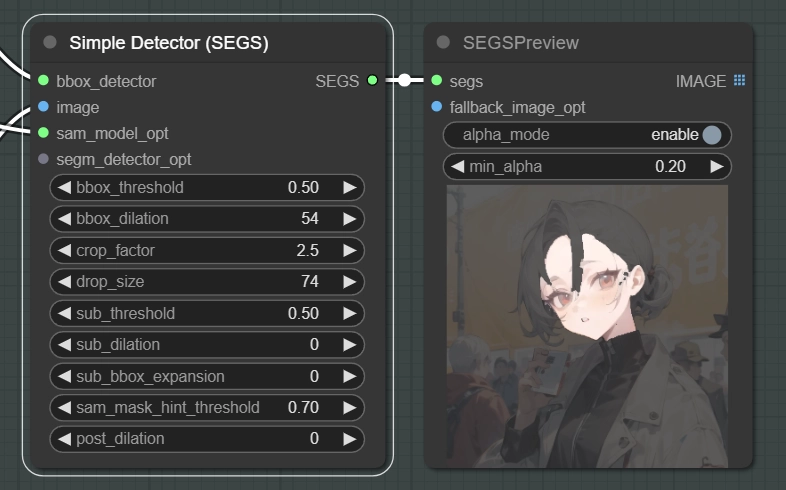
bbox_dilationはBBOXで生成されたマスクを膨張(dilation)するためのパラメータで、
sub_dilationはSAMによって生成されたマスクを膨張するためのパラメータです。
用途不明の設定
sub_bbox_expansion:BBOX_DETECTOR によって検出されたバウンディングボックス(bbox)を拡大するためのパラメータです。bbox_dilationと何が違うのか分かりません。
sam_mask_hint_threshold
post_dilation:正確な意図は分かっていませんが、主処理(セグメンテーション)が完了した後に、結果のマスクを更に膨張したい場合に使う設定だと思います。今のところ用途不明です。
Face DetailerとDetailer (SEGS)は同じ?
Detailerには "Face Detailer" という顔を修正するための専用のノードが用意されています。
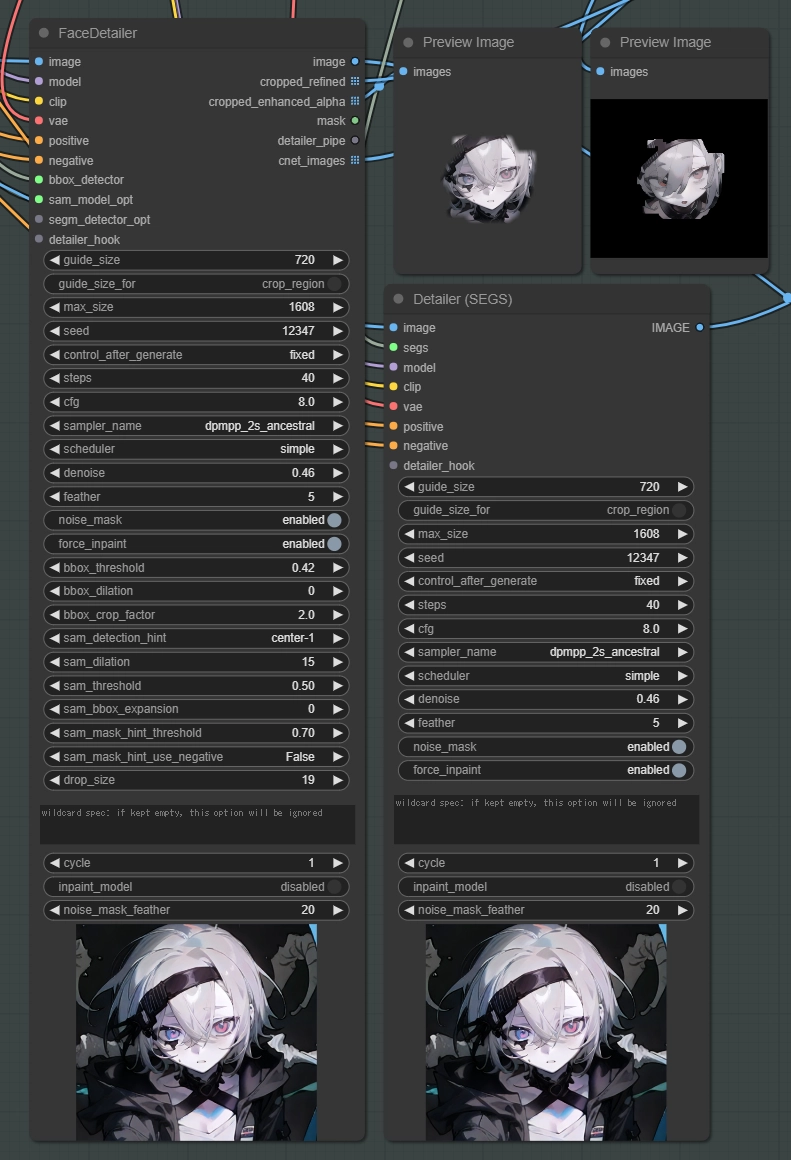
この二つは内部構造が全く違うという訳ではなく、基本的に同じ処理が行われているので結果は特に変わりません。
どういう用途でこのノードあるのか不明ですが、Detectorが内蔵されているおかげでDetectorの調整をする際に生成も同時に行わないといけません。
なので今回この記事でFace Detailerを紹介しなかった理由は拡張性や利便性の薄さ、透明性の低さがあったので紹介しませんでした。
おわりに
正直まだまだ分かってないことだらけのカスタムノードです。
しかし個人的に必須級のカスタムノードになったので今後も使い続ける予定です。
面白いことを発見したら随時記事を更新していこうと思います。
ControlNet + Detailerの使い方は長くなりそうなのでまた次の記事で書きます。






コメント
コメント一覧 (3件)
マイニングウィルスが見つかった影響で、ultralyticsdetectorproviderはimpact subpackに分離されたそうです。
subpackのissueにある様に、現時点ではnumpy等のバージョン不一致が生じてインストールエラーになるかもしれません。
初心者の方は戸惑われるかと思いましたのでコメントしておきます。
https://comfyui-wiki.com/ja/news/2024-12-05-comfyui-impact-pack-virus-alert
https://github.com/ltdrdata/ComfyUI-Impact-Pack/issues/843
https://github.com/ltdrdata/ComfyUI-Impact-Subpack
勉強になった!今までよく分からず他のinpaintカスタムノードと組み合わせて自力でAdetailerみたいな事をしてました。Impact Pack単体で出来たんだ。知れてよかった。教えていただきありがとうございます!
いつも参考にさせていただいております。
ADetailerと比較して顔のみリファインできるのがいいですね、こちらの拡張機能に切り替えさせていただきました。ありがとうございます。
おそらく意図的かと思われ大変恐縮なのですが、
I2Iのポストなどでもサンプルに使われていらっしゃる、こちらのモデルが大変個性的でかわいらしく、とても気になっています。
つり目三白眼八重歯と当方にとって役満なのです。
もし差し支えなければモデル名やLORA名などお教えいただけないでしょうか。
マージレシピや、自作のため公開は出来ない、などのお答えでも助かります。
記事内容と関連が薄く不躾で申し訳ありませんが、お答えいただけると幸いです。
どうかよろしくお願いいたします。