
赤ちゃん用のComfyUIステップアップガイドです。みんなもComfyUIを使いこなしてみよう!
赤ちゃんでも分かるように解説

どうもこの記事を書いているナッツです。ComfyUIはもう使える状態ですか?
まだの方は次の記事から始めてください。

モデルについて
1.モデルのダウンロード場所はCivitAI
2.ダウンロードしたモデルは checkpoints に置く。
ComfyUI → models → checkpoints
txt2imgとは
「text to image」の略語でテキストから画像を作る工程を指します。更に略すと「t2i」と書いたりします。
基本的に「画像を生成する」と言ったら9割はtxt2imgの手法を使います。
必要に応じてimg2imgやinpaintのワークフロー(処理の流れ)が必要になってきます。
では一緒にtxt2imgのワークフローを作っていきましょう。
txt2imgの解説
今回はComfyUIが用意してくれているデフォルトのワークフローを使って解説していきます。
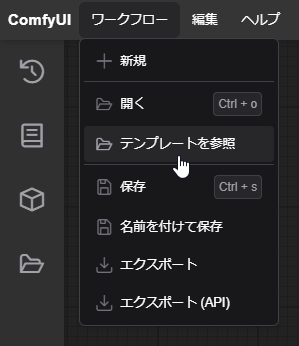
デフォルトのワークフローを呼び出したい場合は
ワークフロー タブの テンプレートを参照 から呼び戻せます。

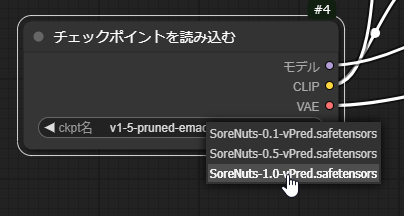
チェックポイント(モデル)の選択
ダウンロードしたモデルを選択してモデルを切り替えましょう。
プロンプトについて

実際にどんな画像が生成されるかはプロンプト(指示)によって全て決まります。
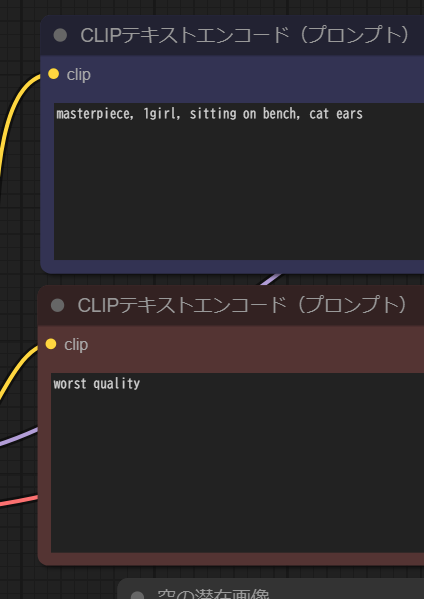
プロンプトを書く場所は「CLIPテキストエンコード(プロンプト)」です。
同じ名前のノードが2つ並んでいます。
それぞれ、指示を書く場所(ポジティブプロンプト)と指示したものを出さないようにする(ネガティブプロンプト)に分けられています。
一般的に違いを一目で分かるようにするために色を変更している場合が多いです。ポジティブは青、ネガティブは赤、など
これらは、Kサンプラーと呼ばれる「画像を生成するノード」にそれぞれが繋がっています。
ノードの種類自体は同じですが、接続先が違うだけでノードの意味が変わってきます。
またプロンプトは英語で書くことがほぼ必須です。※基本的に学習に英語が使われている為
どんなプロンプトを書けばいいか分からない場合は私の記事を参考にしてみてください。




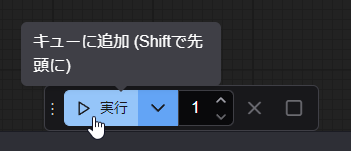
準備は整った!生成してみよう。
画面下にある「実行」から生成できます。
安心してください。すぐに良くなりますよ。まだ良い画像を作るテクニックを何も実践していません。
まず初めに絶対に変えないと話にならない設定を変えましょう。
適切な解像度
モデルによって最適な解像度は変わりますが、現在あるモデルのほとんどが「1024x1024」を推奨しています。
これはモデルのトレーニングが "1024x1024" で行われているためです。
実際に大きくすればするほど破綻が多くなり、不自然なプロポーション(頭身)が発生します。
設定は 空の潜在画像 ノードから変更できます。
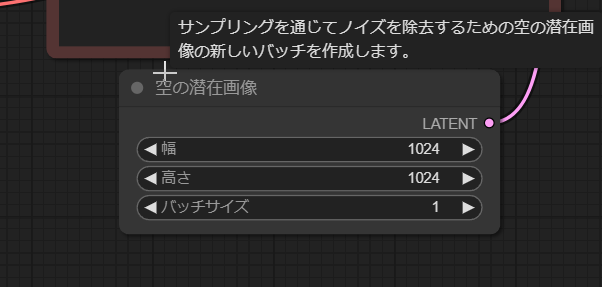
海外でもシェアされている解像度を紹介します。
640 x 1536
768 x 1344
832 x 1216
896 x 1152
1024 x 1024
1152 x 896
1216 x 832
1344 x 768
1536 x 640
注意点としてこれらは全て8の倍数で構成されています。
理由は複雑な要因があってSDモデルは8の倍数しか画像を生成できないためです。
これは人によっては結構重要なので絶対覚えておいてください。
つまり、1100x900と指定しても実際に生成される画像は1104x904となり、強制的に8の倍数に変更されてしまいます。
さあこれで良くなったかな?ん?
落ち着いてください。次の設定で本当に良くなります。
品質を上げるプロンプト
少し前に「プロンプトによって全て決まる」と大袈裟に言いましたが、実は過言ではありません。
次のプロンプトを試してください。
1・ポジティブプロンプトにmasterpiece(傑作)を入れる
2・ネガティブプロンプトにworst quality(最低品質)を入れる
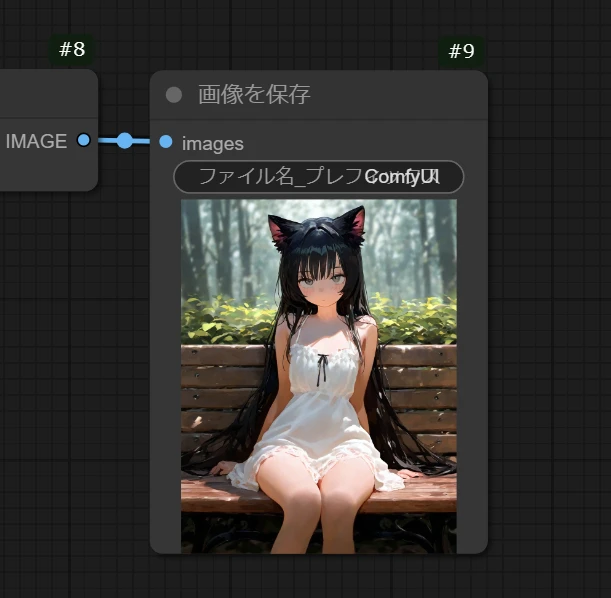
来ました。大きく品質が上がりましたね。
そうなんです。たったこれだけでここまで変わります。ここから先は深淵なので気を付けてください・・・。
画像の保存先
保存された画像は「ComfyUI」フォルダ内の「output」にあります。
ComfyUIフォルダ内に、
outputがあります。
画像の保存先を変更する方法についてはこちらをご覧ください。

フォルダ分けするのに便利ですよ。
Batch処理

Batch処理とは同時に複数の枚数を生成することです。効率的にGPUを使うことができます。
Empty Latent Image ノードを探してください。こちらのノードで生成される解像度を設定できます。
またBatch処理も設定もこちらで行うことができます。「Batch size」が Batch処理の枚数になります。
豆知識: 潜在画像って?
潜在画像はLATENTともいいます。
簡単にいうと、人間には理解しにくい圧縮された「小さな画像データ」です。
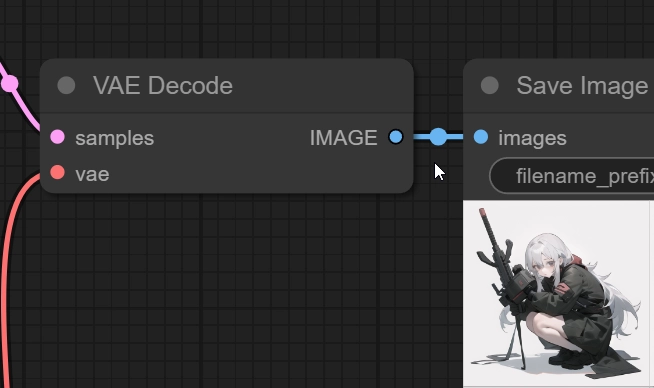
VAE Decodeではこれを人間が理解できる形(.png)へ変換してくれます。
サンプリング方法を変えてみる
「KSampler」を見てみましょう。KSampler とは画像を生成するノードです。
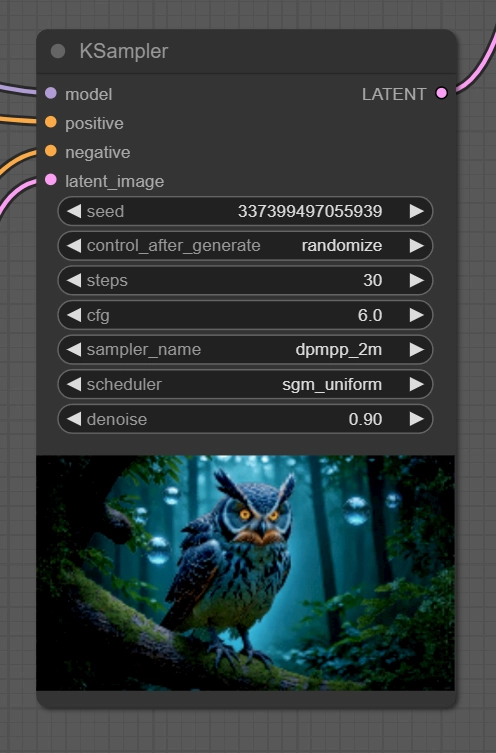
「sampler_name」と「scheduler」が重要な部分です。
ここは完全に好みなので指定はありませんが、今回は有名な「DPM++ 2M Karras」の指定方法を紹介します。
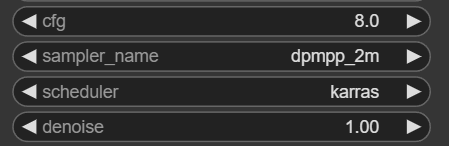
「sampler_name」はdpmpp_2mを選びます。dpmppはDPM++のことです。「scheduler」はkarrasですね。
sampler?scheduler?何?
サンプラー(sampler_name)は「どのように」サンプリングを行うかを決定します。
スケジューラー(scheduler)は「いつ」「どのようなペースで」サンプリングの各ステップを行うかを制御します。

CFGとStepsについては深くは触れませんが、CFGはプロンプトの強さを決めて、Stepsは総ステップ数で、ノイズを徐々に除去します。Stepsが多ければ多いほど品質が良くなる傾向にありますが、50以上だと変化はほぼありません。また、サンプラーによっても必要なステップ数は変わります。Denoiseはノイズの量で、img2imgの時に使います。
LoRA
次にLoRAを追加する方法を解説します。

LoRAとは追加学習によって作成された画風やキャラクターに影響を与える小さなモデルです。もしLoRAをお持ちでないなら、今はスキップしてもらって構いません。
何もない箇所で「ダブルクリック」をしてみましょう。検索窓が表示されます。
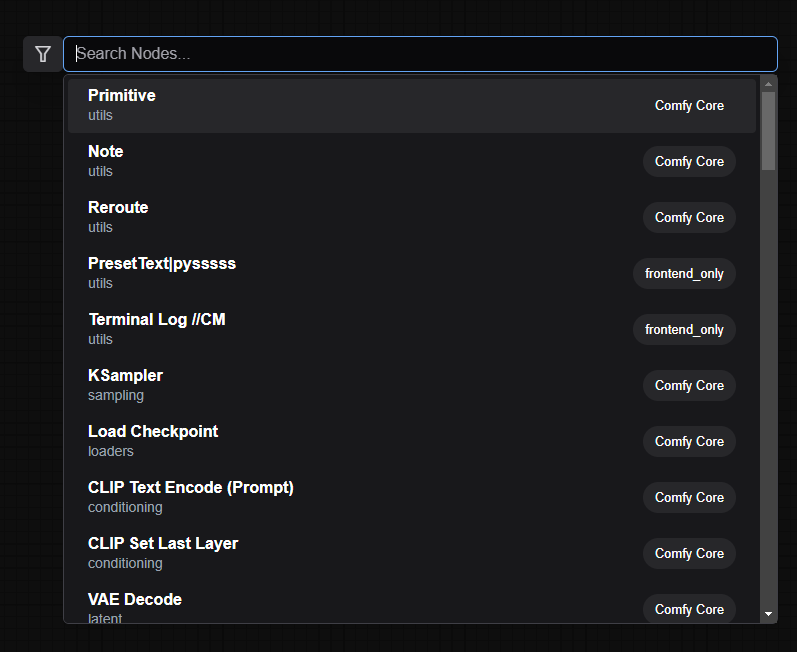
ここに「lora」と打ち込んで「LoraLoader」を選択しましょう。
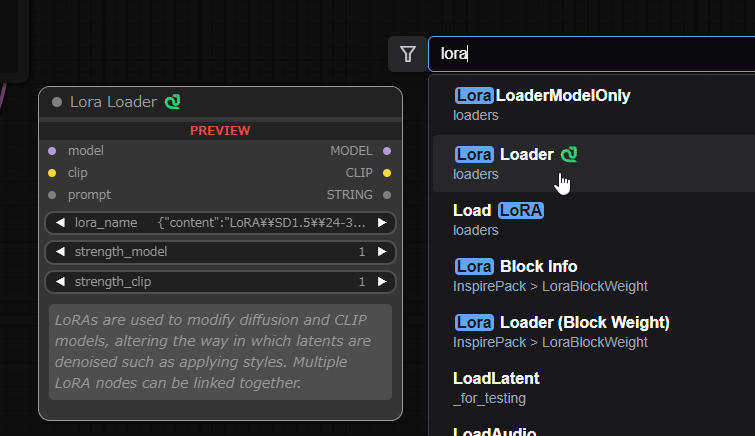
「Load LoRA」を呼び出せました。この方法は覚えておくと後々便利です。
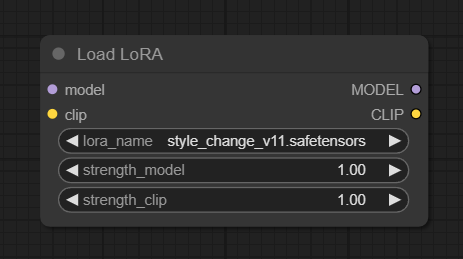
これを「Load Checkpoint」の次に繋ぎます。
複数のLoRAを使いたい場合は「Load LoRA」を増やすだけです。「Altキー」を押しながらノードをクリックすることで複製できます。「Ctrl+C」でコピーして「Ctrl+V」で貼り付けることもできます。
Load LoRAには項目が二つありますが、特に考えずに「strength_model」と「strength_clip」は基本的に「同じ値」にしましょう。
「strength_model」の数値が大きくなれば LoRAの効果が大きくなります。
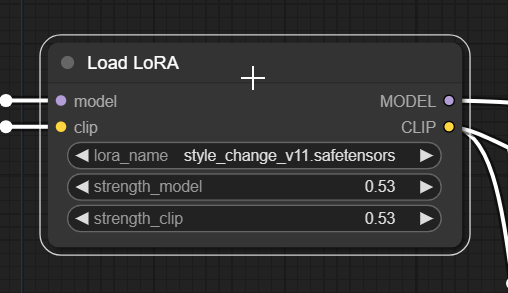
strength_clipについては現時点では全く気にしなくて大丈夫です。未だに筆者も良く分かっていません。
strength_clipについてredditの質問まとめ
モデル強度(model strength)を上げると、生成される画像が学習画像により近くなります。 クリップ強度(clip strength)を上げると、プロンプトによって学習データ内の特徴やトリガーワードがより活性化されます。
通常、モデル強度とクリップ強度は相関が高いのですが、学習データのスタイルは取り入れつつ、特定のキーワードは避けたい場合など、両者を別々に調整したい状況もあります。
LoRAの設定において:
- clip strengthは、テキストの指示(プロンプト)にどの程度従うかを決めます
- model strengthは、LoRAを適用するベースモデルにどの程度影響を与えるかを決めます
ただし、これらのパラメータを0.01変更するだけでも、生成される画像に大きな影響を与えることがあります。
まとめ
これで一般的な「txt2img」のワークフローが作れました。
細かい設定や、難しいノードは使わずに最速で使いこなす方法を書きました。
分からないことがあればお気軽にコメントしてみてください。






コメント