
SoreNutsからのお知らせ
新規記事![]() 5/3に既存のプロンプトをローカルLLMを使って拡張【ComfyUI IF AI tools】を公開!
5/3に既存のプロンプトをローカルLLMを使って拡張【ComfyUI IF AI tools】を公開!![]() 5/1にWildcardでプロンプトとLoRAのランダム化【ComfyUI】を公開!
5/1にWildcardでプロンプトとLoRAのランダム化【ComfyUI】を公開!
更新記事![]() 5/5に環境・背景・場所のプロンプト(呪文)一覧を更新!
5/5に環境・背景・場所のプロンプト(呪文)一覧を更新!![]() 5/3にカメラ・構図のプロンプト(呪文)一覧を更新!
5/3にカメラ・構図のプロンプト(呪文)一覧を更新!![]() 5/1に服装のプロンプト(呪文)一覧を更新!
5/1に服装のプロンプト(呪文)一覧を更新!
Stable Diffusion Web UIのインストール方法と使い方まとめ。ローカル版Automatic1111のダウンロードから上級者になるまでの方法を初心者でも分かるように解説しています。
初歩: Stable Diffusionについて
Stable Diffusionは「テキスト」から「画像」を生成することに特化しているツールです。
クラウド上で動くMidjourneyと違い、「ローカル版」というユーザーのPCに直接インストールして使う無料のソフトウェアです。
最大のメリットはカスタマイズ性に優れている点で、自分の目的に合った画像やイラストが作れることはもちろん、自分で作ったモデルを使うこともできます。






また、拡張機能の追加により動画も作れるようになっています。
意外と簡単に作れるのでこちらの記事も参考にしてみてください。

前提条件
- PCが必要 CPUはあまり使わないのでなんでもいいです。
- GPUが必要 GeForce GTX 1050 Ti(VRAM 4GB)以上
※Macでも動きますが今回はWindowsのインストール方法を紹介します。
必要なソフトのダウンロード
Stable Diffusionだけでは動かないので、必要なソフトをインストールする必要があります。
Python 3.10.6
Pythonというソフト(プログラミング言語)が必要不可欠なのでダウンロードしてインストールしていきましょう。
ダウンロード先
https://www.python.org/downloads/release/python-3106/
※最新版ではなく必ず3.10.6にしてください。
公式が推奨しているバージョンです。

下にスクロールしてWindows installer (64-bit)をダウンロードしましょう。

ダウンロード完了後、そのファイルを実行してインストールを進めましょう。
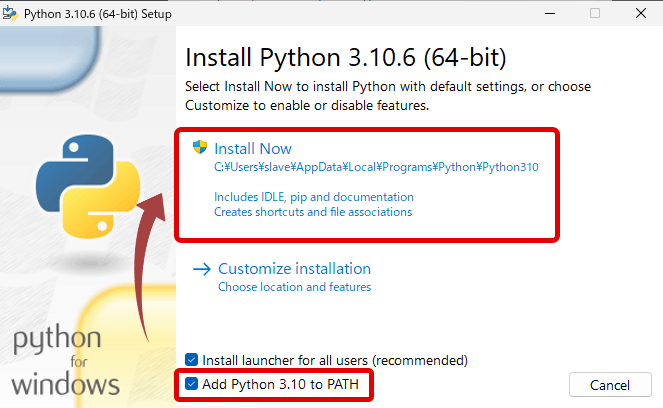
必ず Add Python 3.10 to PATHにチェックを入れてください。
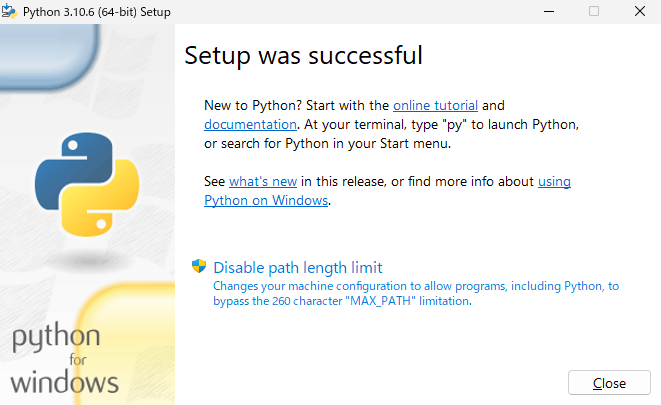
この画面が表示されればインストール完了です。
git
こちらも必須なのでダウロードしていきましょう。

Click here to download
もしくは
64-bit Git for Windows Setup
どちらでも最新バージョンがダウンロードされます。
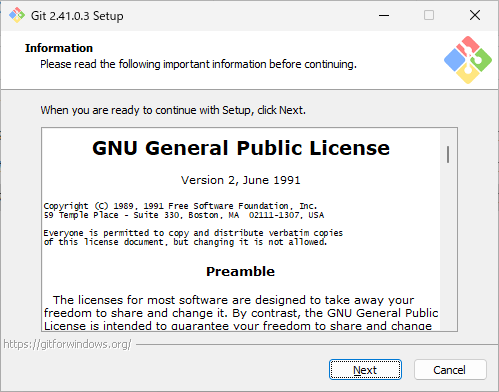
こちらはインストールが始まるまでNextを押し続けます。
全てデフォルト設定で構いません。
この画面が表示されたら完了です。
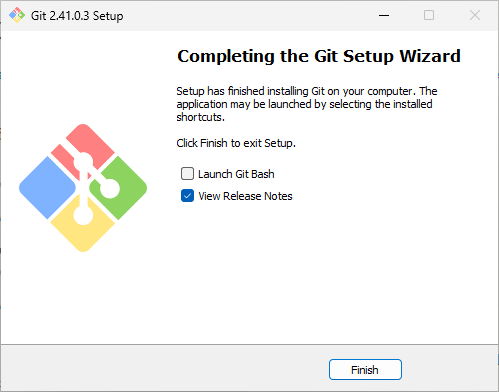
Automatic1111のダウンロード
Automatic1111とはStable Diffusionをブラウザ上で簡単に操作できるアプリケーションです。
現状ではStable Diffusion利用者のほとんどがこのAutomatic1111という「Web UI(Web User Interface)」を使っています。
Stable Diffusionをインストールするフォルダを自分で決めましょう。
どこでも構いません。
おすすめはCドライブやDドライブの直下です。
※パスがシンプルで予期せぬ問題を回避できる可能性があるため
今回はCドライブ直下にSDというフォルダを作りました。
※Stable Diffusionの略称
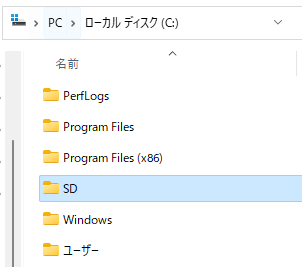
さらに今後のことを考えて複数のStable Diffusionを管理しやすくするためにmain1というフォルダを作りました。
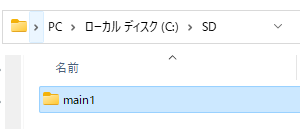
main1フォルダに移動し、左上のパスにcmdと入力しEnterキーでcmd(コマンドプロンプト)を起動します。

cmdに
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitこちらをコピーしてペーストしましょう。
あとはEnterキーで自動的にダウンロードが行われ、数秒で完了します。
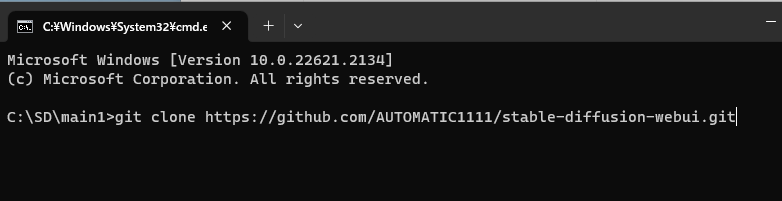
ダウンロードが終わったらcmdは閉じてください。
正常にダウンロードされていたらstable-diffuison-webuiというフォルダが追加されます。

Stable Diffusionを起動する
stable-diffusion-webuiのフォルダ内のwebui-userで起動します。
種類がWindows バッチ ファイルになっているものです。
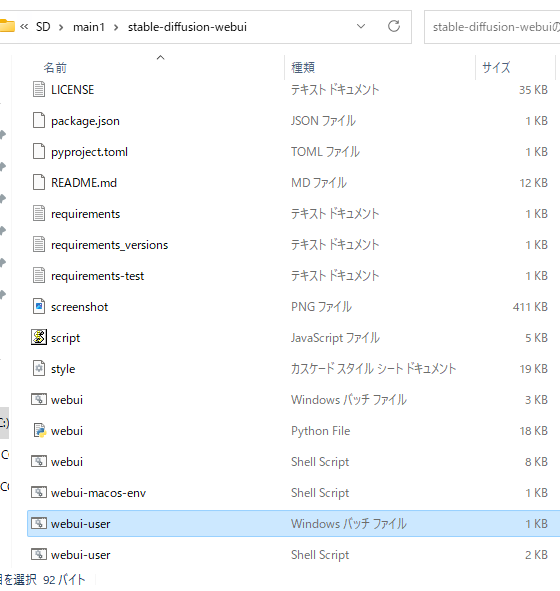
※拡張子を表示している人はwebui-user.batになっているので分かりやすいです。

初回起動時には必要なライブラリやファイルが大量にダウンロードされます。
このステップは1時間ほど掛かる場合があります。回線速度に大きく左右されます。


ブラウザで開く
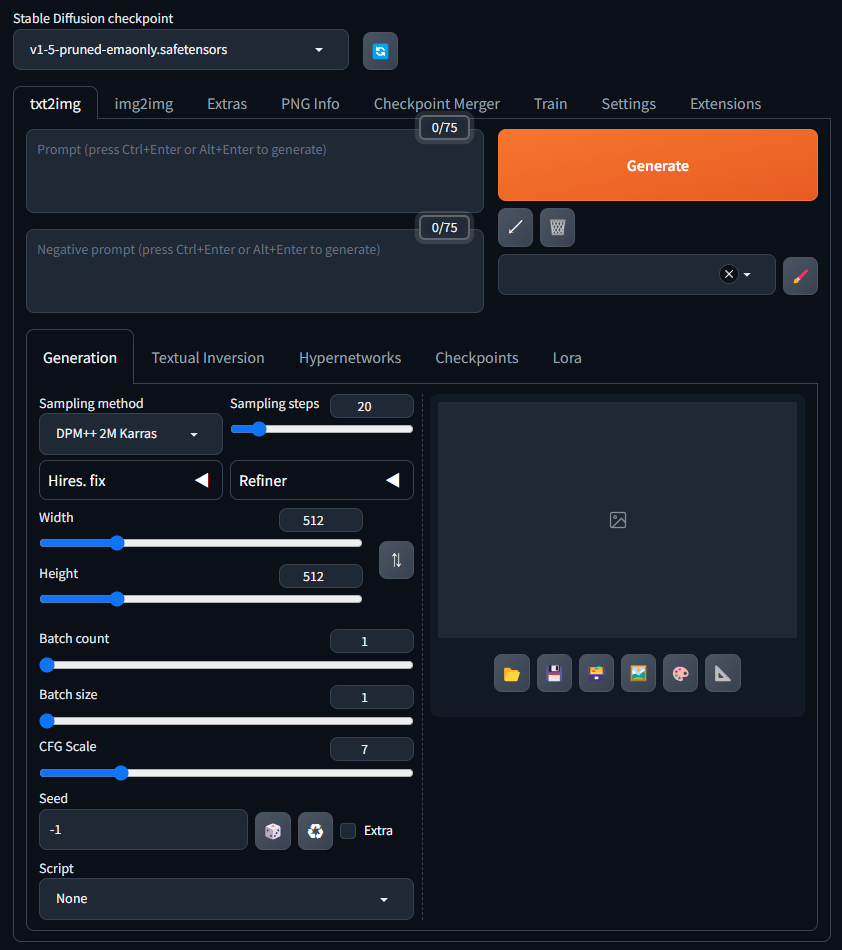
最新バージョンではcmdを起動すると自動的に表示されているURL「http://127.0.0.1:7860」にアクセスしてくれます。
こちらがStable Diffusionのメイン画面です。
筆者の環境ではPCをダークモードにしているためStable Diffusionもダークテーマになっています。
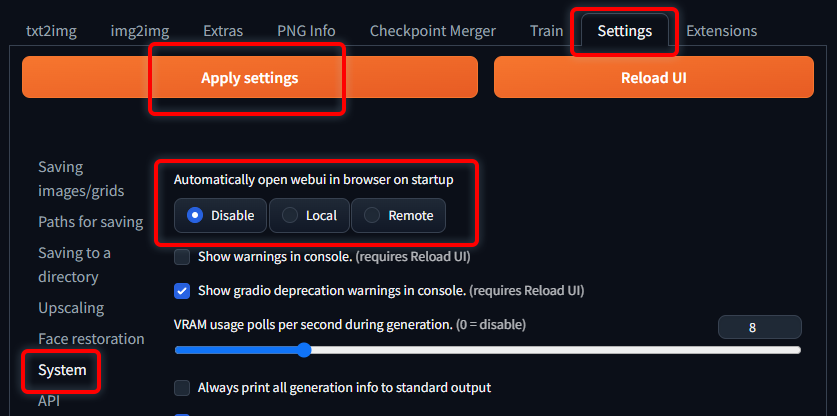
Tips: 自動的に起動してほしくない場合
Settingsタブ → System → Disable → Apply settings
メイン画面の解説
上部の説明
左上が現在のモデル名です。「v1-5-pruned-emaonly.safetensors」となっています。
モデルが選択されていない場合はクリックして選択しましょう。
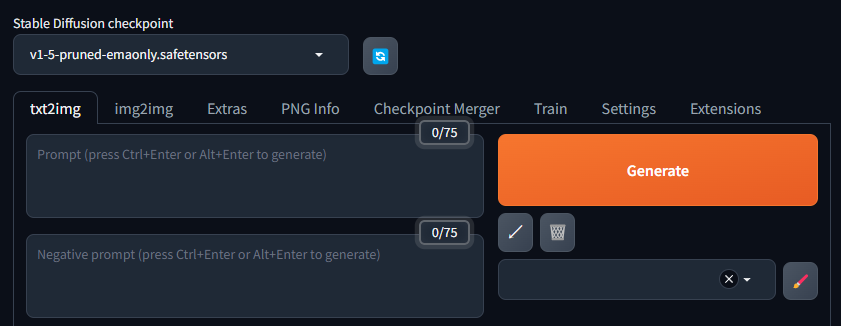
こちらは初回起動の時にダウンロードされた簡易的なモデルです。品質が低い画像しか作れません。
「txt2img」とは「text to image」の略語であり、テキストを画像に変換することを意味します。
「img2img」とは「image to image」の略語であり、画像を別の画像に変換することを意味します。
基本は「テキスト」から「画像」を作ることがメインになっています。
タブの下に薄い文字で「Prompt」とありますね。日本語で「プロンプト」や「呪文」と呼ばれることが多いです。
これはAIモデルに対する”指示“です。こちらに書いた「テキスト」が「画像」に変換されます。
続いてその下にある「Negative prompt」とはここに書いた「テキスト」を生成結果から除外することができます。
こちらはカタカナで「ネガティブプロンプト」と呼ばれています。
例えば「green」と入力すると緑色の要素が出なくなり、「low quality」(品質が悪い)と入力すれば品質が悪い画像が除外されます。
では次は実際に作ってみましょう。
一枚生成してみる
Promptに「dog」と入れて生成してみましょう。右上のGenerateボタンが生成という意味です。
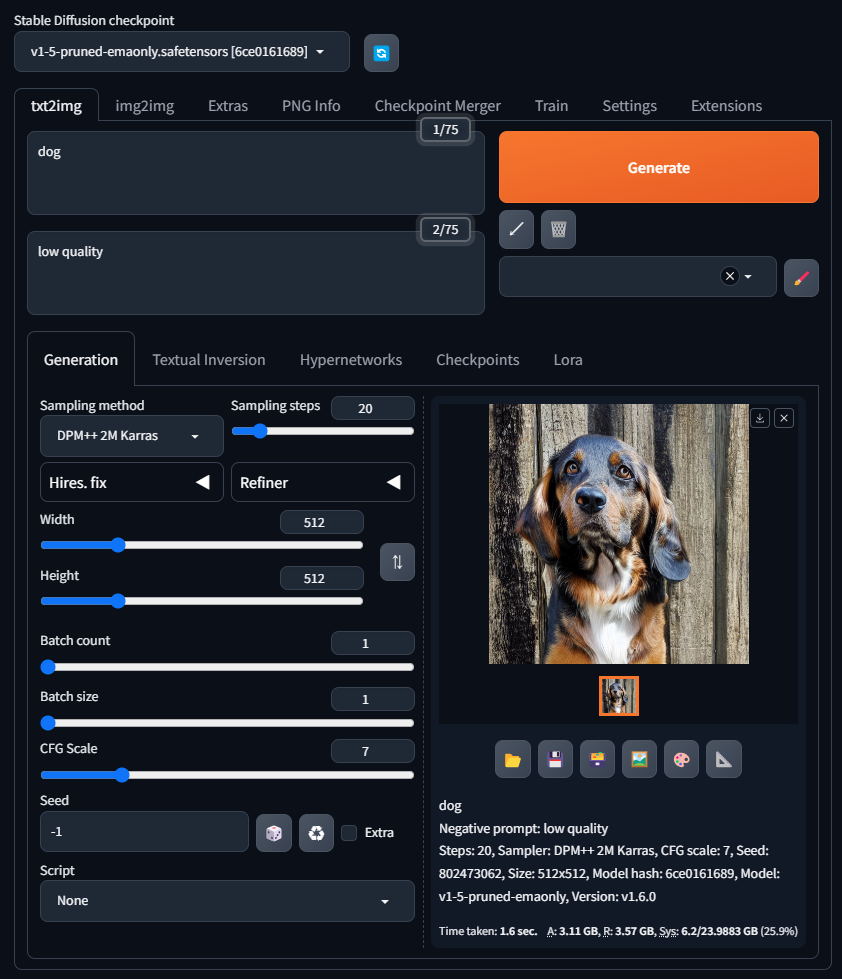
無事に生成できたら犬の画像が表示されるはずです。お疲れさまでした。
この一枚が生成できるまで様々なエラーや問題がある場合が多いので、ここまでノンストップで来れた人は幸運です。
プロンプトの書き方については、次の記事の「レベル1: 基礎」までを習得することをおすすめします。

下部の説明

Generation 生成に関する一般的な設定は全てここで行います。
Textual Inversion 現在は「Embedding」と呼ばれることが多いです。非常に軽量なファイルであることが多く、代表的なのは「EasyNegative」と呼ばれるもので、ネガティブプロンプトにeasynegativeと記載すると多様な種類の「品質の悪い画像」を除外してくれます。
しかし、何が学習されているか分からないので、完全におまかせモードということになります。制御が難しいため筆者は一切使っておらず、ある程度自分で検証したネガティブプロンプトを使っています。
記事の最後にロードマップがあり、その中にネガティブプロンプトについての記事を書いているのでもっと知りたい方は参考にしてみてください。
Hypernetworks 画像を学習させて特定の画風やキャラクターを再現することができます。
しかし、この点においては「LoRA」のほうが圧倒的に優秀であり、使う必要は全くありません。
実際にHypernetworksをダウンロードしようとすると1か月以内に1つしかファイルがなく、利用者や開発者もほとんど存在しません。
Checkpoints 日本語で「モデル」と言われています。メイン画面上部の左上から切り替えることができますが、こちらでも同様にサムネイルをクリックするだけで切り替えることができます。
このようにサムネイルと説明文をカスタマイズして整理することができます。
右上の赤い工具から設定を変更できます。
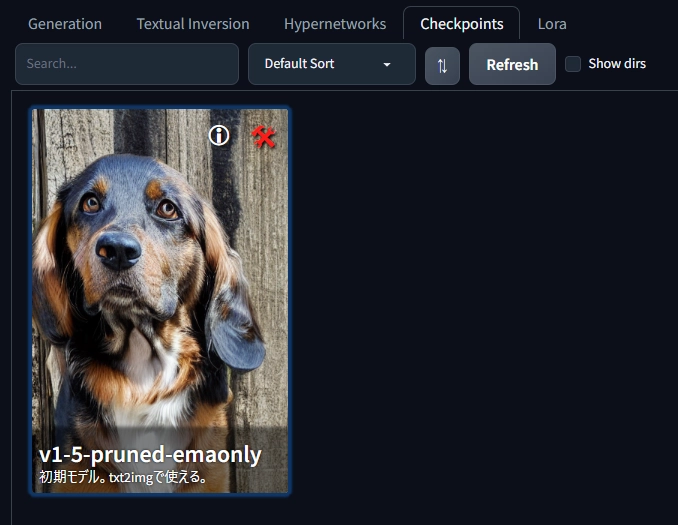
機能は説明する必要はないくらいシンプルです。Replace previewは「現在生成している画像」を差し替えます。

自分が作ったオリジナルのサムネイルを使うことも可能です。比率やサイズはなんでもいいです。

その場合は次のフォルダに移動して
stable-diffusion-webui/models/Stable-diffusionファイルを差し替えるだけです。モデル名と同じ名前にする必要があります。
差し替えた後はRefreshボタンから更新をして確認してみましょう。
Lora “Low-Rank Adaptation”の略称で、大量のデータや情報を、簡略化しつつもその本質を保った形で扱いやすく変換する技術の一つです。
そのまま「LoRA」として呼ばれることが多いです。
現在選択しているモデルに「追加コンテンツ」を導入します。内容は「画風」「特定のキャラクター」「ポーズ」「服装」が主流です。
追加コンテンツなので、同時に使うことになります。気にするほどではないですが、LoRAを同時に使いすぎると生成に時間が掛かるようになっていきます。
ほとんどのLoRAはCivitaiというサイトに集中しており、全て無料でダウンロードすることができます。
Generationの解説
日本語で「サンプラー」と呼ばれることが多いです。
ノイズを消すための手順を決めるものをサンプラーと言います。
Sampling steps はノイズを除去する回数です。多ければそれだけノイズが取り除かれることになります。
しかし、その回数はサンプラーごとに違いはあるものの、基本的に「20」以上にしても変化はあまりありません。
「100のほうが綺麗なんでしょ」と思って「100」に上げると生成時間は「20」と比べると単純に”5倍“になるのでおすすめしません。
「2」Steps

「8」Steps

「20」Steps

「30」Steps

「40」Steps

「100」Steps

筆者はちょっといい品質を作ろうと思って「30」にしていたのですが、何が変化したか認識できないレベルなので現在は「20」にしています。

「Hires.fix」は低解像度で生成した画像を、高解像度にするための補助ツールです。
本来は「txt2img」で生成した低解像度の画像を「img2img」で高解像度化するのですが、この一連の流れを自動で行ってくれる機能です。
詳しい使い方を知りたい方はこちらの記事を参考にしてみてください。

「Refiner」はSDXLという次世代のモデル専用の機能です。残念ながらSDXLは実写以外は生成することがとても苦手なので筆者はあまり検証していません。
「Refiner」を使えば綺麗にノイズを取り除くことができるようになります。要するにRefinerを使えば品質が高まるということです。
Refinerのダウンロード先
https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/tree/main
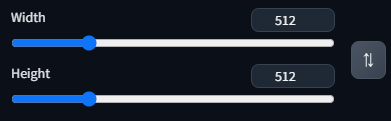
横の長さが「Width」で縦の長さが「Height」です。
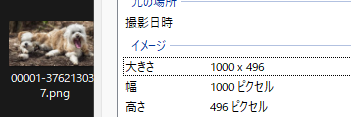
注意点として”8の倍数“しか生成できません。例えば解像度が”1000×500″の画像を生成するとします。

しかし、”500″は8の倍数ではないので、8で割り切れる496が使われます。
16:9の画像を作りたい場合は1024×576がおすすめです。

「Batch count」は何回繰り返すか。
「Batch size」は同時に何枚処理するか。
Batch countが「20」になっていれば「20回繰り返し生成する」ことになります。これはVRAM消費量に影響しません。
Batch sizeが「6」になっていれば「6枚同時」に生成されます。これはVRAM消費量に影響しますが、生成時間を短縮できます。
Batch sizeが「6」、Bacth countが「20」になっていれば「120枚」生成されることになります。
Batch sizeを増やすことによって実際にどれくらい生成時間が短縮できるのか試してみました。
| Batch count「6」 | Time taken: 9.8 sec. |
| Batch count「3」Batch size「2」 | Time taken: 8.2 sec. |
| Batch count「2」Batch size「3」 | Time taken: 8.0 sec. |
| Batch size「6」 | Time taken: 7.8 sec. |
最大で20.41%短縮される結果になりました。

CFGは「Classifier Free Guidance」の略で、画像生成プロセスがテキストプロンプトにどれだけ従うかを制御するパラメーターです。
プロンプトの影響を強くしたり弱くしたりすることができます。
CFG Scale「1」

CFG Scale「3」

CFG Scale「5」

CFG Scale「7」

CFG Scale「10」

CFG Scale「15」

これはモデルやClip Skipといった別の要素に大きく左右されるので、ご自身の好みに合った設定を探してみてください。

seed値とは、乱数生成器の初期状態を設定するための数値のことです。
「-1」に設定しているとランダムなseed値が割り振られます。
同じseed値を使えば、同じ生成結果が得られます。
異なるseed値を使えば、異なる結果が得られます。

サイコロをクリックすると「-1」に設定されます。
リサイクルのようなボタンは「現在生成している画像」のseed値に設定されます。あまり使いません。
Extraは上級者向けの機能なのでここでは解説しませんが、「Variation」と書いてある通りバリエーションを作成することができます。

筆者は全く使わない機能です。

こちらも上級者向けの機能となっています。

特に「X/Y/Z plot」は検証や大量生成に必要不可欠なので、また詳しく書いた記事を作ろうと思います。
最前線までの簡易ロードマップ
※※ロードマップの記事を随時更新※※
初期モデルでは作りたいものはまず作れないでしょう。まずは核となる「モデル」を変更しましょう。

(worst quality, low quality:1.4)プロンプトの書き方について少し説明します。
かっこで囲んだプロンプトは倍率を指定することができるようになり、強調されます。(効果が強くなります)

ほぼ必須アイテムです。分かりやすく解説しています。

品質が安定して高く、使い勝手が良いサンプラーです。
使用者が非常に多いため、デフォルトで選択されるようになりました。

サンプラーは極めて多くありますが、ハッキリ言って違いは分かりません。
筆者はサンプラーの記事を作ろうとしましたが違いが分からず発狂しました。
明らかに品質が向上するサンプラーが見つかり次第記事を更新しますが、個人で検証することは強くおすすめしません。
もしあなたが「ひとつの画像」にこだわりたい方なら、この記事は読まなくても良いです。現在筆者はこの機能は使っていません。
必要に応じてこのオプションを使いましょう。
有効化する手順は簡単で

「webui-user.bat」をメモ帳で開きます。
「set COMMANDLINE_ARGS=」の後に
--xformersという引数を入力して上書き保存しましょう。ショートカットキーは「Ctrl+S」です。
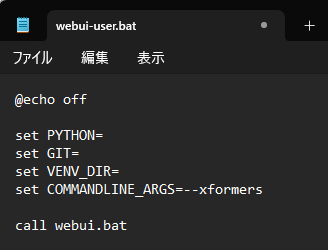
もし引数を追加したい場合は半角スペースを必ず開ける必要があります。
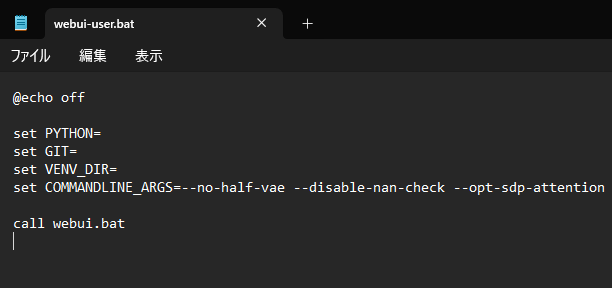
--no-half-vaeと--disable-nan-checkはエラー回避のために入れておくことをおすすめします。
もっと引数の種類を知りたい方は
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Command-Line-Arguments-and-Settings
全て英語ですが、こちらの公式Wikiを参考にしてみてください。




掲示板